文字参考自海量数据处理算法—Bloom Filter.
Bloom Filter(BF)是一种空间效率很高的随机数据结构,它是一个判断元素是否存在集合的快速的概率算法。Bloom Filter有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter判断元素不再集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误。因此,Bloom Filter不适合那些“零错误”的应用场合。
基本思想
计算某元素x是否在一个集合中,首先能想到的方法就是将所有的已知元素保存起来构成一个集合R,然后用元素x跟这些R中的元素一一比较来判断是否存在于集合R中;我们可以采用链表等数据结构来实现。但是,随着集合R中元素的增加,其占用的内存将越来越大。
于是,我们会想到用Hash table的数据结构,运用一个足够好的Hash函数将一个值映射到二进制位数组(位图数组)中的某一位。如果该位已经被置为1,那么表示该值已经存在。
Hash存在一个冲突(碰撞)的问题,两个值用同一个Hash得到的可能有相同的index。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便是Bloom-Filter的基本思想。
算法模块
数据结构
Bloom Filter使用一个m比特的数组来保存信息,初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0,即BF整个数组的元素都设置为0。

元素添加
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。
当我们往Bloom Filter中增加任意一个元素x时候,我们使用k个哈希函数得到k个哈希值,也会是在数组中的下标index,然后将数组中对应的比特位设置为1。
如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位,即第二个“1“处)。
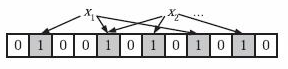
元素查找
在判断y是否属于这个集合时,我们只需要对y使用k个哈希函数得到k个哈希值,如果所有hashi(y)的位置都是1(1≤i≤k),即k个位置都被设置为1了,那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素(因为y1有一处指向了“0”位)。y2或者属于这个集合,或者刚好是一个false positive误判。
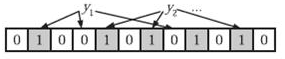
Python实现
安装
1pip install pybloom使用
1234567from pybloom import BloomFilter, ScalableBloomFilterbf = BloomFilter(capacity=10000, error_rate=0.001)bf.add('test')print 'test' in bfsbf = ScalableBloomFilter(mode=ScalableBloomFilter.SMALL_SET_GROWTH)sbf.add('dddd')print 'ddd' in sbfBloomFilter是一个定容的过滤器,error_rate是指最大的误报率是0.1%,而ScalableBloomFilter是一个不定容量的布隆过滤器,它可以不断添加元素。add方法是添加元素,如果元素已经在布隆过滤器中,就返回true,如果不在返回fasle并将该元素添加到过滤器中。判断一个元素是否在过滤器中,只需要使用in运算符即可了。