Scipy基于Numpy,提供了大量科学算法,它的不同子模块相应于不同的应用,本文参考了1 2
- 文件IO(scipy.io):数据输入输出
- 特殊函数(scipy.special):特殊函数是先验函数,常用的有伽马函数scipy.special.gamma()
- 线性代数运算(scipy.linalg)
- 快速傅里叶变化(scipy.fftpack)
- 优化和拟合(scipy.optimize):提供了函数最小值(标量或多维)、曲线拟合和寻找等式的根的有用算法。
- 统计和随机数(scipy.stats)
- 数值积分(scipy.integrate Fusy)
模块导入的标准方式是:
|
|
文件输入/输出:scipy.io
导入和保存matlab文件
|
|
图片读取
|
|
txt/csv
|
|
线性代数运算:scipy.linalg
行列式
|
|
逆矩阵
|
|
奇异值分解SVD
|
|
快速傅里叶变换:scipy.fftpack
优化和拟合:scipy.optimize
标量函数最小值
|
|
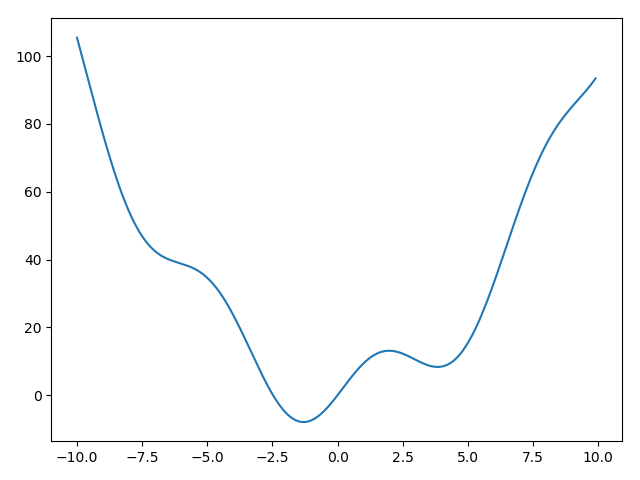
|
|
|
|
标量函数的根
|
|
曲线拟合
|
|
统计和随机数: scipy.stats
直方图和概率密度函数
|
|
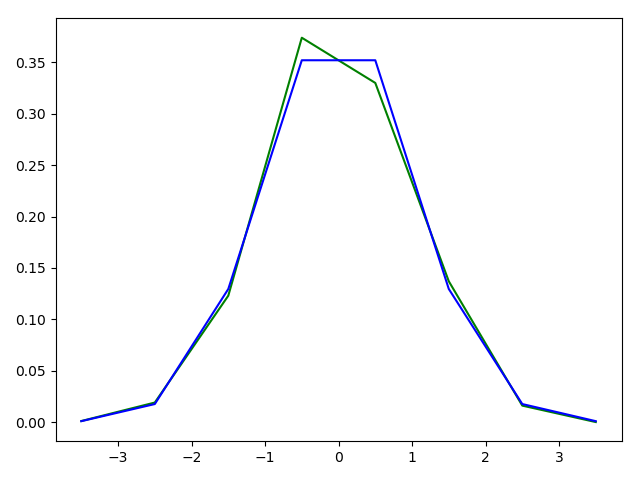
|
|
百分位
|
|
数值积分:scipy.integrate Fusy
|
|
上述计算$\int_{0}^{\frac{\pi}{2}}sin(x)dx=1$