本文参考1
pandas导入
|
|
琐碎
read_csv()默认有表头,会跳过第一行,从第二行开始读起。如果我们要读取的文件,直接就是数据,没有所谓的表头,就需 read_csv(header=None).
when bad lines exist in file:
12ERROR : pandas.errors.ParserError: Error tokenizing data. C error: Expected 1024 fields in line 237, saw 1491data = pd.read_csv('file1.csv', error_bad_lines=False)
数据结构
Pandas处理以下三种数据结构:系列(Series),数据帧(DataFrame),面板(Panel)
系列是具有均匀数据的一维数组结构,尺寸大小不变但数据可变
数据帧(DataFrame)是一个具有异构数据的二维数组,尺寸大小可变且数据可变
面板是具有异构数据的三维数据结构,尺寸大小可变且数据可变
系列(Series)
系列(Series)是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组,轴标签统称为索引。
|
|
创建系列
创建一个空的系列
|
|
ndarray创建一个系列
|
|
从字典创建一个系列
|
|
从标量创建一个系列
|
|
系列访问
使用位置index访问
|
|
使用标签检索
|
|
数据帧(DataFrame)
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
|
|
创建数据帧
|
|
通过列表创建
可以使用单个列表或列表列表创建数据帧(DataFrame)
|
|
通过ndarrays/Lists的字典创建
所有的ndarrays必须具有相同的长度。如果传递了索引(index),则索引的长度应等于数组的长度。
如果没有传递索引,则默认情况下,索引将为range(n),其中n为数组长度。
|
|
通过字典创建
字典列表可作为输入数据传递以用来创建数据帧(DataFrame),字典键默认为列名。
|
|
通过系列创建
字典的系列可以传递以形成一个DataFrame。 所得到的索引是通过的所有系列索引的并集。
|
|
数据帧访问
列选择
|
|
列添加
|
|
列删除
列可以删除或弹出
|
|
行选择
|
|
行切片
可以使用:运算符选择多行
|
|
附加行
使用append()函数将新行添加到DataFrame
|
|
删除行
使用索引标签从DataFrame中删除或删除行。 如果标签重复,则会删除多行。
|
|
面板(Panel)
Pandas基本功能
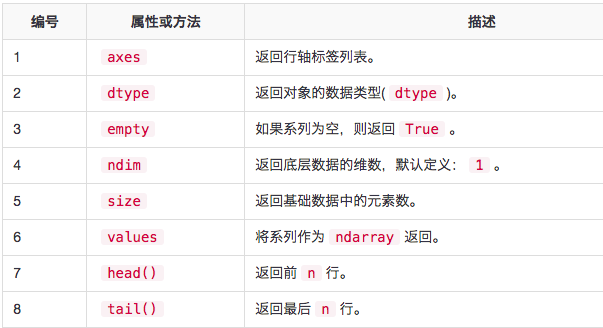
系列基本功能
|
|
axes
|
|
empty
返回布尔值,表示对象是否为空。返回True则表示对象为空。
|
|
ndim
返回对象的维数。根据定义,一个系列是一个1D数据结构
|
|
size
返回系列的大小(长度)
|
|
values
|
|
head-tail
head()返回前n行(观察索引值)。要显示的元素的默认数量为5,但可以传递自定义这个数字值。
tail()返回最后n行(观察索引值)。 要显示的元素的默认数量为5,但可以传递自定义数字值。
|
|
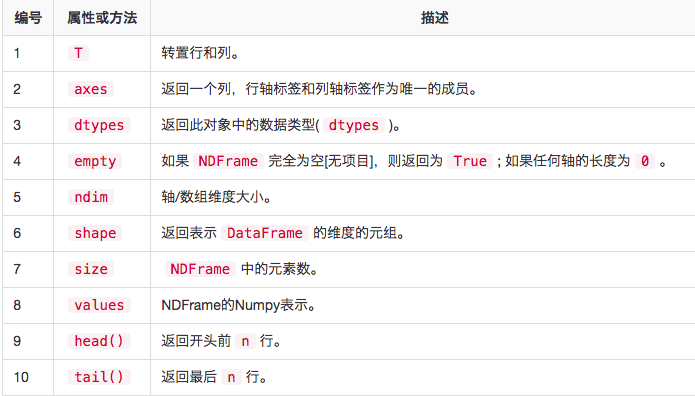
DataFrame基本功能
Pandas描述性统计
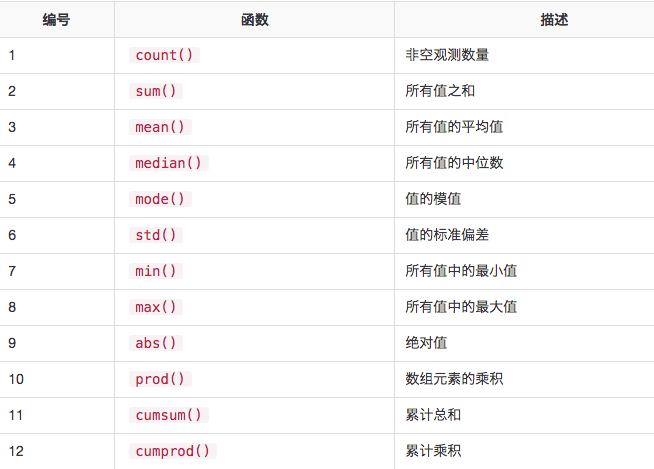
- 类似于:
sum(),cumsum()函数能与数字和字符(或)字符串数据元素一起工作,不会产生任何错误。字符聚合从来都比较少被使用,虽然这些函数不会引发任何异常。- 当DataFrame包含字符或字符串数据时,像
abs(),cumprod()这样的函数会抛出异常。
创建一个数据帧
|
|
| Age | Name | Rating | |
|---|---|---|---|
| 0 | 25 | Tom | 4.23 |
| 1 | 26 | James | 3.24 |
| 2 | 25 | Ricky | 3.98 |
| 3 | 23 | Vin | 2.56 |
| 4 | 30 | Steve | 3.20 |
| 5 | 29 | Minsu | 4.60 |
| 6 | 23 | Jack | 3.80 |
| 7 | 34 | Lee | 3.78 |
| 8 | 40 | David | 2.98 |
| 9 | 30 | Gasper | 4.80 |
| 10 | 51 | Betina | 4.10 |
| 11 | 46 | Andres | 3.65 |
sum()
返回所请求轴的值的总和。 默认情况下,轴为索引(axis=0),即对列sum
|
|
axis=1,则对行sum
|
|
mean()
与sum()用法一样,默认是对列求均值;mean(1)则是对每一行求均值。
std()
返回数字列的Bressel标准偏差。
数据汇总
describe()函数是用来计算有关DataFrame列的统计信息的摘要。
|
|
include是用于传递关于什么列需要考虑用于总结的必要信息的参数。获取值列表; 默认情况下是”数字值”。
object- 汇总字符串列number- 汇总数字列all- 将所有列汇总在一起(不应将其作为列表值传递)
|
|
Pandas函数
以下三种方法是要将自己或其他库的函数应用于Pandas对象,使用适当的方法取决于函数是否期望在整个DataFrame,行或列或元素上进行操作。
- pipe() : 表明智函数应用
- apply() : 行或列函数应用
- applymap() : 元素函数应用
pipe表格函数
可以通过将函数和适当数量的参数作为管道参数来执行自定义操作。 因此,对整个DataFrame执行操作。例如,为DataFrame中的所有元素相加一个值2。
|
|
appy行或列智能函数应用
可以使用apply()方法沿DataFrame或Panel的轴应用任意函数,它与描述性统计方法一样,采用可选的轴参数。 默认情况下,操作按列执行,将每列列为数组。指定axis=1,则按照行执行
|
|
|
|
applymap元素智能函数
并不是所有的函数都可以向量化(也不是返回另一个数组的NumPy数组,也不是任何值),在DataFrame上的方法applymap()和类似地在Series上的map()接受任何Python函数,并且返回单个值。
|
|
Pandas重建索引
重新索引会更改DataFrame的行标签和列标签。重新索引意味着符合数据以匹配特定轴上的一组给定的标签。
可以通过索引来实现多个操作 -
- 重新排序现有数据以匹配一组新的标签。
- 在没有标签数据的标签位置插入缺失值(NA)标记。
|
|
重建索引与其他对象对齐
有时可能希望采取一个对象和重新索引,其轴被标记为与另一个对象相同。
|
|
注意 - 在这里,
df1数据帧(DataFrame)被更改并重新编号,如df2。 列名称应该匹配,否则将为整个列标签添加NAN。
填充时重新加注
reindex()采用可选参数方法,它是一个填充方法,其值如下:
pad/ffill- 向前填充值bfill/backfill- 向后填充值nearest- 从最近的索引值填充
|
|
注 - 最后四行被填充了。
重建索引时的填充限制
限制参数在重建索引时提供对填充的额外控制。限制指定连续匹配的最大计数
|
|
注意 - 只有第
7行由前6行填充。 然后,其它行按原样保留。
重命名
rename()方法允许基于一些映射(字典或者系列)或任意函数来重新标记一个轴。
|
|
Pandas迭代
Pandas对象之间的基本迭代的行为取决于类型。当迭代一个系列时,它被视为数组式,基本迭代产生这些值。其他数据结构,如:DataFrame和Panel,遵循类似惯例迭代对象的键。
简而言之,基本迭代(对于i在对象中)产生 -
- Series - 值
- DataFrame - 列标签
- Pannel - 项目标签
DataFrame迭代
要遍历数据帧(DataFrame)中的行,可以使用以下函数 -
iteritems()- 迭代(key,value)对iterrows()- 将行迭代为(索引,系列)对itertuples()- 以namedtuples的形式迭代行
注意 - 不要尝试在迭代时修改任何对象。迭代是用于读取,迭代器返回原始对象(视图)的副本,因此更改将不会反映在原始对象上。
|
|
iteritems()
将每个列作为键,将值与值作为键和列值迭代为Series对象。
|
|
iterrows()
iterrows()返回迭代器,产生每个索引值以及包含每行数据的序列。
|
|
itertuples()
itertuples()方法将为DataFrame中的每一行返回一个产生一个命名元组的迭代器。元组的第一个元素将是行的相应索引值,而剩余的值是行值。
|
|
Pandas排序
Pandas有两种排序方式,它们分别是 -
- 按标签
- 按实际值
以标签排序
使用sort_index()方法,通过传递axis参数和排序顺序,可以对DataFrame进行排序。 默认情况下,按照升序对行标签进行排序。
通过传递axis参数值为0或1,可以对列标签进行排序。 默认情况下,axis = 0,逐行排列。
|
|
以值排序
像索引排序一样,sort_values()是按值排序的方法。它接受一个by参数,它将使用要与其排序值的DataFrame的列名称。
|
|
通过by参数指定需要列值。
|
|
先对col1列排序,使该列有序,同时col2也对应变化为3,2,4,1.接着对col2列排序,这时对前一列相同的值情况下再排序,即3,2,4排序为2,3,4.这样前一列还是有序的
Pandas索引和数据选择
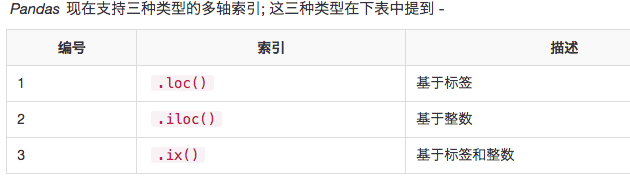
.loc()
.loc()具有多种访问方式,如 -
- 单个标量标签
- 标签列表
- 切片对象
- 一个布尔数组
loc需要两个单/列表/范围运算符,用","分隔。第一个表示行,第二个表示列
|
|
.iloc()
Pandas提供了各种方法,以获得纯整数索引。像python和numpy一样,第一个位置是基于0的索引。
各种访问方式如下 -
- 整数
- 整数列表
- 系列值
|
|
.ix()
除了基于纯标签和整数之外,Pandas还提供了一种使用.ix()运算符进行选择和子集化对象的混合方法。
|
|
多轴索引
使用基本索引运算符[]
|
|
可以使用属性运算符.来选择列。
|
|
统计函数
pct_change()函数
系列,DatFrames和Panel都有pct_change()函数。此函数将每个元素与其前一个元素进行比较,并计算变化百分比。
认情况下,pct_change()对列进行操作; 如果想应用到行上,那么可使用axis = 1参数。
|
|
cov()协方差
协方差适用于系列数据。Series对象有一个方法cov用来计算序列对象之间的协方差。NA将被自动排除。
|
|
当应用于DataFrame时,协方差方法计算所有列之间的协方差(cov)值。
|
|
注 - 观察第一个语句中
a和b列之间的cov结果值,与由DataFrame上的cov返回的值相同。
相关性函数
相关性显示了任何两个数值(系列)之间的线性关系。有多种方法来计算pearson(默认),spearman和kendall之间的相关性。
|
|
如果DataFrame中存在任何非数字列,则会自动排除。
数据排名
数据排名为元素数组中的每个元素生成排名,不是比大小哦。在关系的情况下,分配平均等级。
|
|

Pandas窗口函数
为了处理数字数据,Pandas提供了几个变体,如滚动,展开和指数移动窗口统计的权重。 其中包括总和,均值,中位数,方差,协方差,相关性等。
.rolling()
这个函数可以应用于Series数据。指定window=n参数并在其上应用适当的统计函数。
窗口大小指定几行数据进行运算
|
|
.expanding()
这个函数可以应用于Series数据。 指定min_periods = n参数并在其上应用适当的统计函数。
|
|
.ewm()
ewm()可应用于系列数据。指定com,span,halflife参数,并在其上应用适当的统计函数。它以指数形式分配权重。
|
|
Pandas聚合
当有了滚动,扩展和ewm对象创建了以后,就有几种方法可以对数据执行聚合。
在整个数据框上应用聚合
|
|
在数据框的单个列上应用聚合
|
|
在DataFrame的多列上应用聚合
|
|
在DataFrame的单个列上应用多个函数
|
|
在DataFrame的多列上应用多个函数
|
|
将不同的函数应用于DataFrame的不同列
|
|
Pandas缺失数据
|
|
使用重构索引(reindexing),创建了一个缺少值的DataFrame。 在输出中,
NaN表示不是数字的值。
检查缺失值
为了更容易地检测缺失值(以及跨越不同的数组dtype),Pandas提供了isnull()和notnull()函数,它们也是Series和DataFrame对象的方法
|
|
缺失数据的计算
- 在数据计算时,
NA将被视为0 - 如果数据全部是
NA,那么结果将是0
|
|
缺失数据清理/填充
Pandas提供了各种方法来清除缺失的值。fillna()函数可以通过几种方法用非空数据“填充”NA值
|
|
| 方法 | 行为 |
|---|---|
| pad/fill | 填充的方法向前 |
| bfill/backfill | 填充的方法向后 |
|
|
放弃缺失值
如果只想排除缺少的值,则使用dropna函数和axis参数。 默认情况下,axis = 0,即在行上应用,这意味着如果行内的任何值是NA,那么整个行被排除。
|
|
值替换
很多时候,必须用一些具体的值取代一个通用的值。可以通过应用替换方法来实现这一点。
用标量值替换NA是fillna()函数的等效行为。
|
|
Pandas分组

|
|
数据拆分成组
Pandas对象可以分成任何对象。有多种方式来拆分对象,如 -
- obj.groupby(‘key’)
- obj.groupby([‘key1’,’key2’])
- obj.groupby(key,axis=1)
单列分组
|
|
多列分组
|
|
迭代遍历分组
|
|
选择一个分组
使用get_group()方法,可以选择一个组。
|
|
聚合
聚合函数为每个组返回单个聚合值。当创建了分组(group by)对象,就可以对分组数据执行多个聚合操作。一个比较常用的是通过聚合或等效的agg方法聚合
|
|
另一种查看每个分组的大小的方法是应用size()函数
|
|
一次应用多个聚合函数, 通过分组系列,还可以传递函数的列表或字典来进行聚合,并生成DataFrame作为输出
|
|
转换:分组或列上的转换返回索引大小与被分组的索引相同的对象。因此,转换应该返回与组块大小相同的结果。
|
|
过滤:过滤根据定义的标准过滤数据并返回数据的子集。filter()函数用于过滤数据。
|
|
Pandas合并/连接
Pandas具有功能全面的高性能内存中连接操作,与SQL等关系数据库非常相似。 Pandas提供了一个单独的merge()函数,作为DataFrame对象之间所有标准数据库连接操作的入口
|
|
在这里,有以下几个参数可以使用 -
- left - 一个DataFrame对象。
- right - 另一个DataFrame对象。
- on - 列(名称)连接,必须在左和右DataFrame对象中存在(找到)。
- left_on - 左侧DataFrame中的列用作键,可以是列名或长度等于DataFrame长度的数组。
- right_on - 来自右的DataFrame的列作为键,可以是列名或长度等于DataFrame长度的数组。
- left_index - 如果为
True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 在具有MultiIndex(分层)的DataFrame的情况下,级别的数量必须与来自右DataFrame的连接键的数量相匹配。 - right_index - 与右DataFrame的left_index具有相同的用法。
- how - 它是left, right, outer以及inner之中的一个,默认为内inner。 下面将介绍每种方法的用法。
- sort - 按照字典顺序通过连接键对结果DataFrame进行排序。默认为
True,设置为False时,在很多情况下大大提高性能。
|
|
|
|
on参数
在一个键上合并两个数据帧
|
|
合并多个键上的两个数据框
|
|
how参数

|
|
Pandas级联
Pandas提供了各种工具(功能),可以轻松地将Series,DataFrame和Panel对象组合在一起。
|
|
- objs - 这是Series,DataFrame或Panel对象的序列或映射。
- axis -
{0,1,...},默认为0,这是连接的轴。 - join -
{'inner', 'outer'},默认inner。如何处理其他轴上的索引。联合的外部和交叉的内部。 - ignore_index − 布尔值,默认为
False。如果指定为True,则不要使用连接轴上的索引值。结果轴将被标记为:0,...,n-1。 - join_axes - 这是Index对象的列表。用于其他
(n-1)轴的特定索引,而不是执行内部/外部集逻辑。
|
|
结果的索引是重复的; 每个索引重复。如果想要生成的对象必须遵循自己的索引,请将ignore_index设置为True。
|
|
如果需要沿axis=1添加两个对象,则会添加新列。
|
|
连接的一个有用的快捷方式是在Series和DataFrame实例的append方法。这些方法实际上早于concat()方法。 它们沿axis=0连接,即索引 -
|
|
append()函数也可以带多个对象
|
|
时间序列
Pandas为时间序列数据的工作时间提供了一个强大的工具,尤其是在金融领域。在处理时间序列数据时,我们经常遇到以下情况 -
- 生成时间序列
- 将时间序列转换为不同的频率
获取当前时间
datetime.now()用于获取当前的日期和时间。
|
|
创建时间戳
时间戳数据是时间序列数据的最基本类型,它将数值与时间点相关联。 对于Pandas对象来说,意味着使用时间点。
|
|
创建时间范围
|
|
改变时间频率
|
|
Pandas分类数据
分类对象创建
通过在pandas对象创建中将dtype指定为“category”。
|
|
传递给系列对象的元素数量是四个,但类别只有三个。观察相同的输出类别。
使用标准Pandas分类构造函数,我们可以创建一个类别对象。
|
|
|
|
- 第二个参数表示类别。因此,在类别中不存在的任何值将被视为
NaN- 从逻辑上讲,排序(ordered)意味着,
a大于b,b大于c。
Describe()
|
|
Pandas可视化
线形图
|
|
如果索引由日期组成,则调用
gct().autofmt_xdate()来格式化x轴,如上图所示。我们可以使用
x和y关键字绘制一列与另一列。
条形图
|
|
要生成一个堆积条形图,通过指定:pass stacked=True
|
|
要获得水平条形图,使用barh()方法
|
|
直方图
可以使用plot.hist()方法绘制直方图。我们可以指定bins的数量值。
|
|
要为每列绘制不同的直方图
|
|
箱线图
基本绘图:绘图
Series和DataFrame上的这个功能只是使用matplotlib库的plot()方法的简单包装实现。参考以下示例代码 -
|
|
执行上面示例代码,得到以下结果 -

如果索引由日期组成,则调用gct().autofmt_xdate()来格式化x轴,如上图所示。
我们可以使用x和y关键字绘制一列与另一列。
绘图方法允许除默认线图之外的少数绘图样式。 这些方法可以作为plot()的kind关键字参数提供。这些包括 -
bar或barh为条形hist为直方图boxplot为盒型图area为“面积”scatter为散点图
条形图
现在通过创建一个条形图来看看条形图是什么。条形图可以通过以下方式来创建 -
|
|
执行上面示例代码,得到以下结果 -

要生成一个堆积条形图,通过指定:pass stacked=True -
|
|
执行上面示例代码,得到以下结果 -

要获得水平条形图,使用barh()方法 -
|
|
执行上面示例代码,得到以下结果 -

直方图
可以使用plot.hist()方法绘制直方图。我们可以指定bins的数量值。
|
|
执行上面示例代码,得到以下结果 -

要为每列绘制不同的直方图,请使用以下代码 -
|
|
执行上面示例代码,得到以下结果 -

箱形图
Boxplot可以绘制调用Series.box.plot()和DataFrame.box.plot()或DataFrame.boxplot()来可视化每列中值的分布。
|
|
这里是一个箱形图,表示对
[0,1)上的统一随机变量的10次观察的五次试验。
散点图
|
|
饼状图
|
|
IO工具
Pandas I/O API是一套像pd.read_csv()一样返回Pandas对象的顶级读取器函数。
读取文本文件(或平面文件)的两个主要功能是read_csv()和read_table()。它们都使用相同的解析代码来智能地将表格数据转换为DataFrame对象
|
|

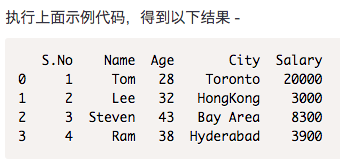
read_csv()
read.csv从csv文件中读取数据并创建一个DataFrame对象。
|
|
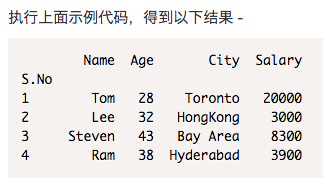
自定义索引
可以指定csv文件中的一列来使用index_col定制索引。
|
|
类型转换器
|
|
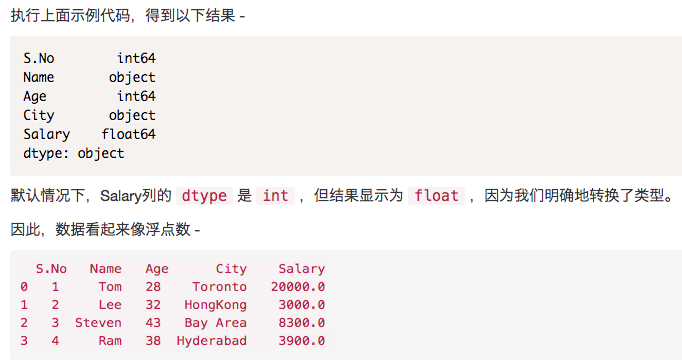
指定列名
使用names参数指定标题的名称。
|
|
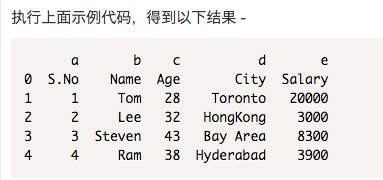
观察可以看到,标题名称附加了自定义名称,但文件中的标题还没有被消除。 现在,使用header参数来删除它。
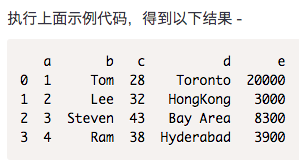
如果标题不是第一行,则将行号传递给标题。这将跳过前面的行。
|
|
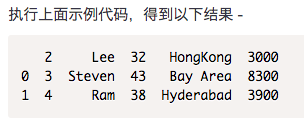
skiprows
skiprows跳过指定的行数
|
|
Pandas稀疏数据
当任何匹配特定值的数据(NaN/缺失值,尽管可以选择任何值)被省略时,稀疏对象被“压缩”。 一个特殊的SparseIndex对象跟踪数据被“稀疏”的地方。 这将在一个例子中更有意义。 所有的标准Pandas数据结构都应用了to_sparse方法
|
|
为了内存效率的原因,所以需要稀疏对象的存在。
现在假设有一个大的NA DataFrame并执行下面的代码
|
|
通过调用to_dense可以将任何稀疏对象转换回标准密集形式
|
|
稀疏Dtypes
稀疏数据应该具有与其密集表示相同的dtype。 目前,支持float64,int64和booldtypes。 取决于原始的dtype,fill_value默认值的更改 -
float64−np.nanint64−0bool−False
|
|
按位布尔
按位布尔运算符(如==和!=)将返回一个布尔系列
|
|
isin()
这将返回一个布尔序列,显示系列中的每个元素是否完全包含在传递的值序列中
|
|