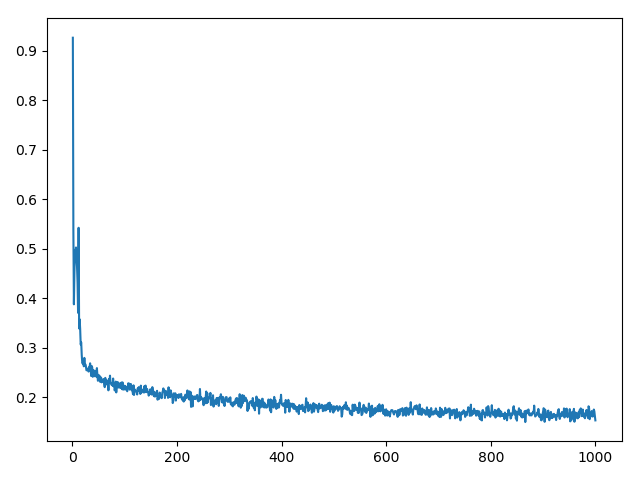
AutoEncoder通过设计encode和decode过程使输入和输出越来越接近,是一种自监督学习过程,输入图片通过encode进行处理,得到code,再经过decode处理得到输出,我们可以控制encode的输出维数,就相当于强迫encode过程以低维参数学习高维特征。
模型
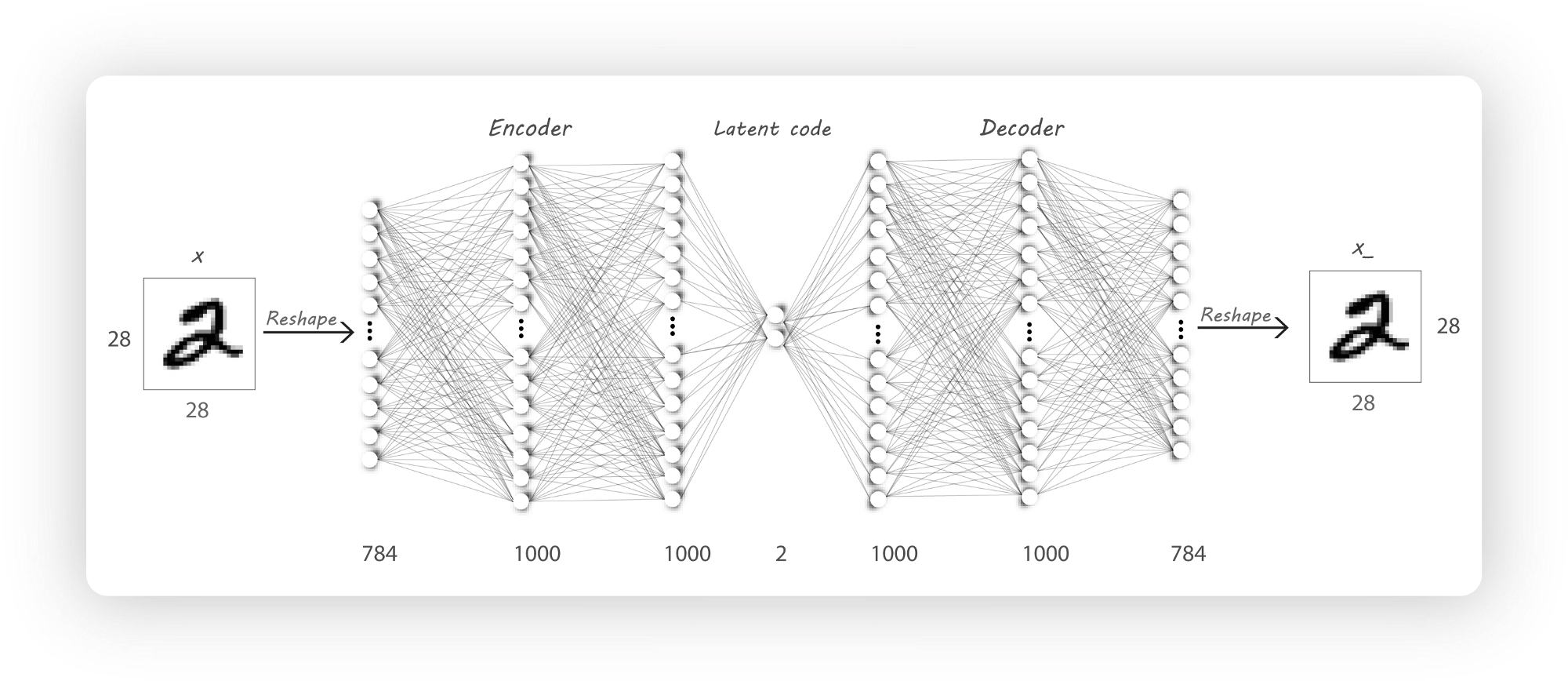
自编码器包含两个部分:encoder和decoder。
encoder的输入是$x$,输出是$h$,通常$h$的维度比$x$少。比如:我们输入encoder一张大小为$100\times 100$大小的图片,输出潜在编码$h$,大小是$100\times 1$。这种情况下,encoder将输入图片映射到了一个低维空间,这样我们只需要很少的空间就可以存储$h$,当然这样的压缩也会丢失一些原始数据的信息。
decoder的输入是潜在编码$h$,并且尝试重构出一张图片。假如$h$的大小是$100\times 1$,decoder试图利用$h$重构一张大小为$100\times100$的图片,我们训练decoder使之输出的图片尽量接近原图。
只有当输入是彼此关联的(比如图片是来自同一个领域),降维才能有效。如果输入是完全随机的图片,降维的效果是很差的。同时这个过程中我们没有使用任何label数据,所以自编码器属于无监督模型。
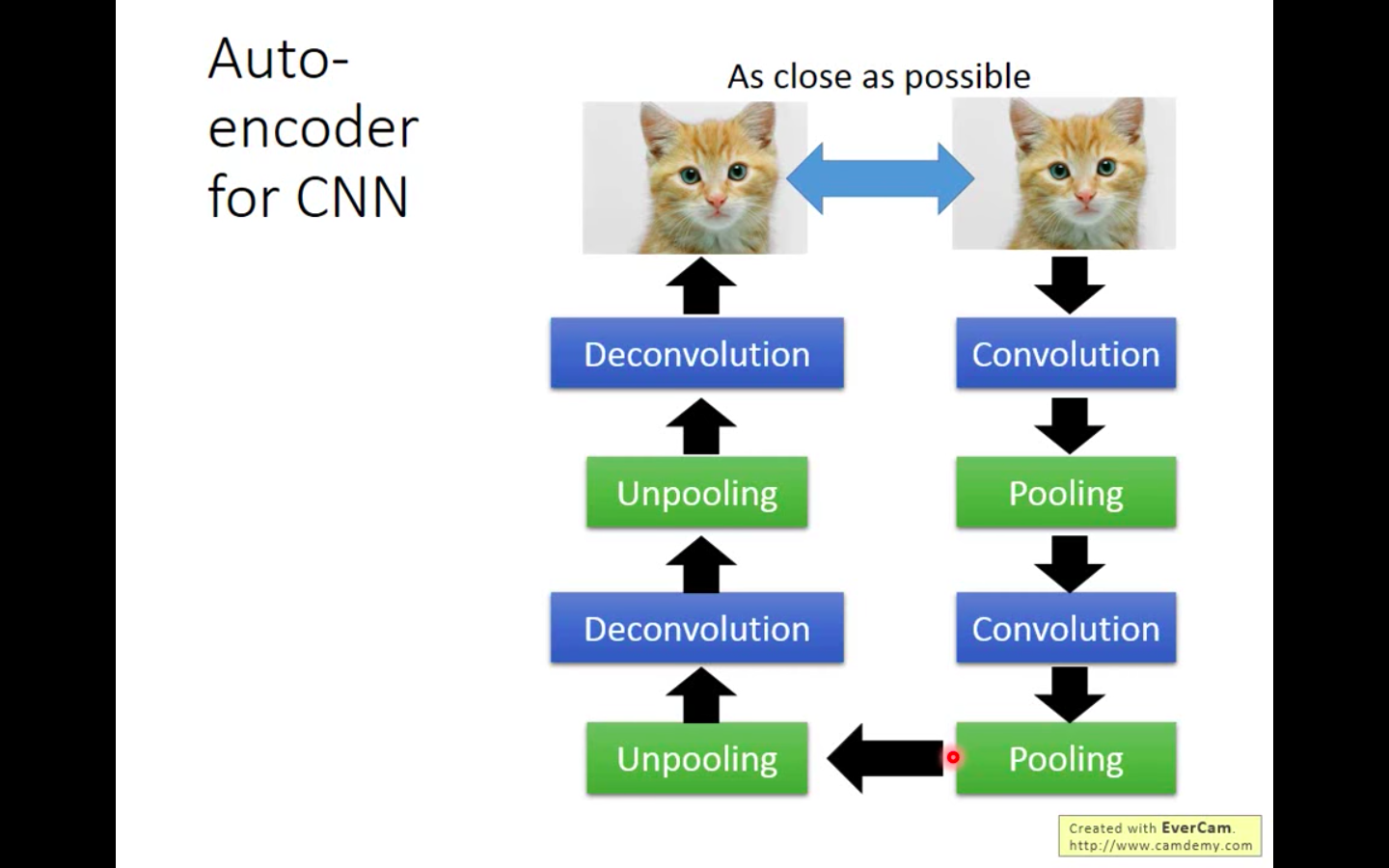
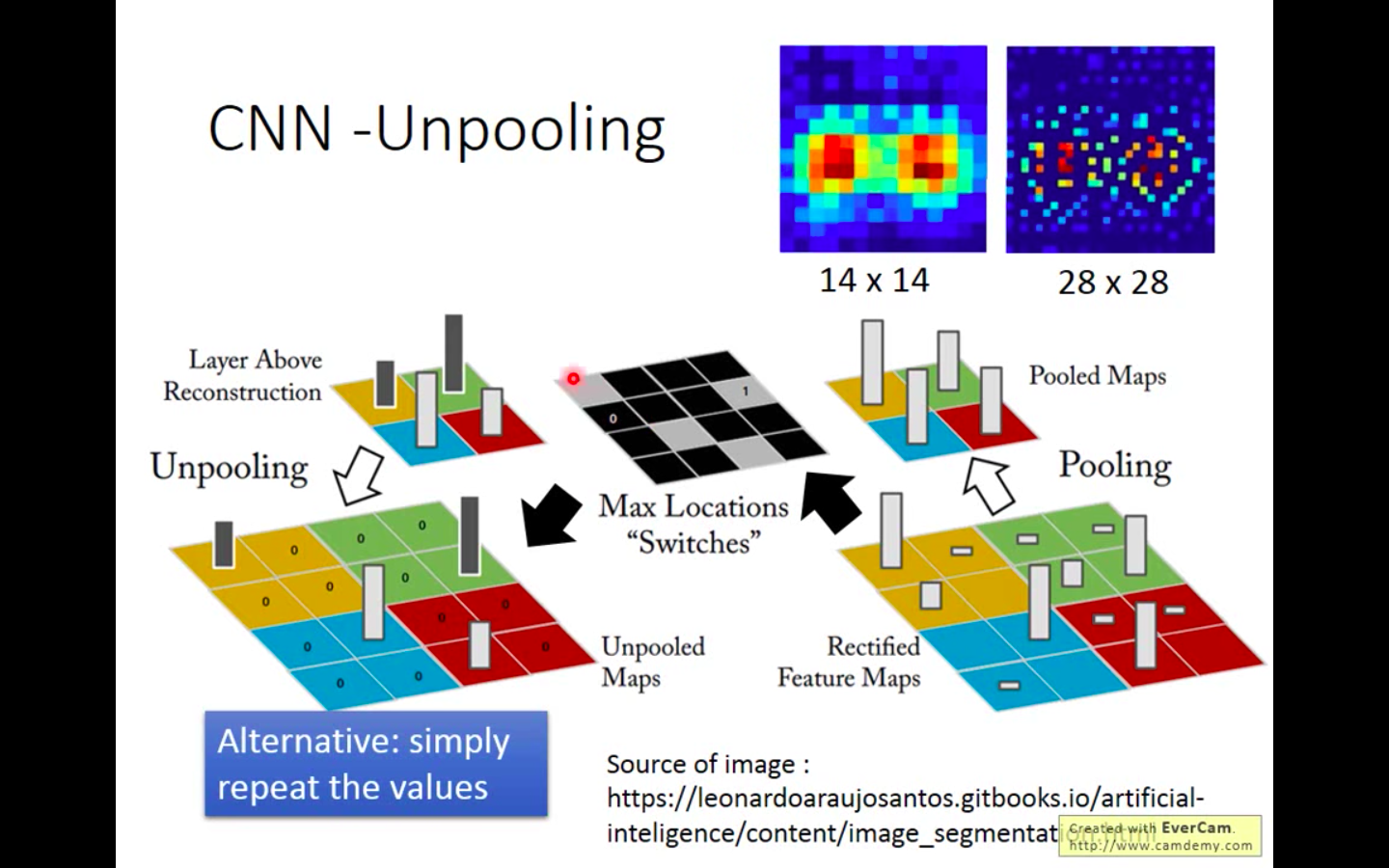
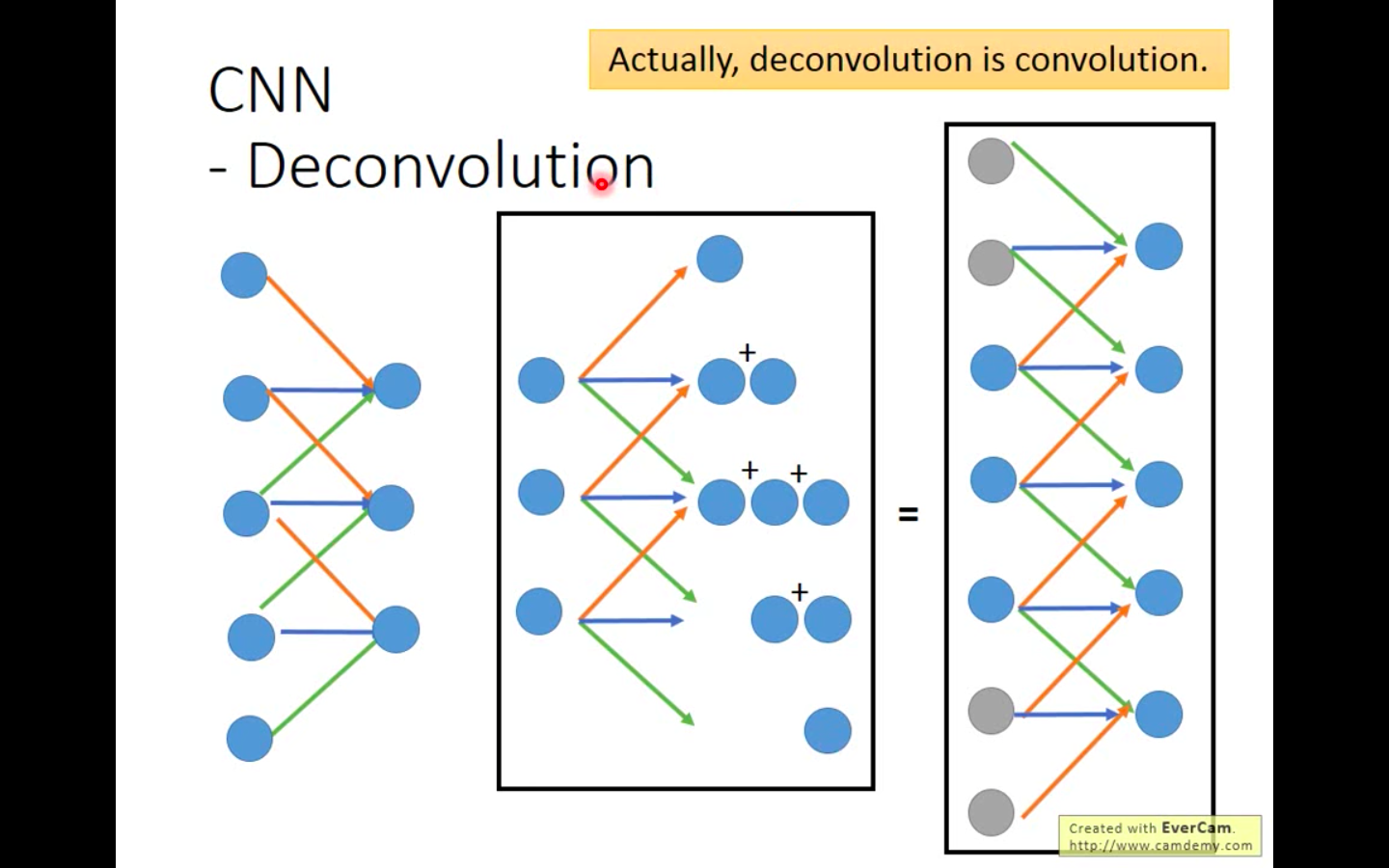
Python实现
|
|