Adversarial Autoencoder
无监督AAE
autoencoder中的encoder的输出(潜在码)并不能在某一特定空间均匀分布,而且AE 的 G 只能保证将由 x 生成的 z 还原为 x。如果我们随机生成 1 个 z,经过 AE 的 G 后往往不会得到有效的图像。
所以我们希望encoder的输出可以服从某一分布,这个分布可以是正态分布,均匀分布等,这样就会使encoder的输出均匀分布在给定的先验分布,使decoder学习到一个先验分布到输入数据的映射(本例中就是学习到MNIST手写体数据的分布),那么此时只需从这个先验分布采样出 z,就能通过 G 得到有效的图像。
假设你正在学习一门课程,如果你的老师并没有提供任何资料,你又会如何学习这门课呢?但是考试怎么办呢,难道要自己瞎答吗?这种情况就是类似我们的encoder的输出并不服从某种特定分布,这样decoder就无法学习到一个从任意数字到图片的映射。
但是如果你有了一个课程指导书,你就可以在考试之前复习这本书,这样就知道了可能的考试内容。类似的,如果我们的encoder输出服从一个已知分布,那么encoder就会将潜在码覆盖整个先验分布。
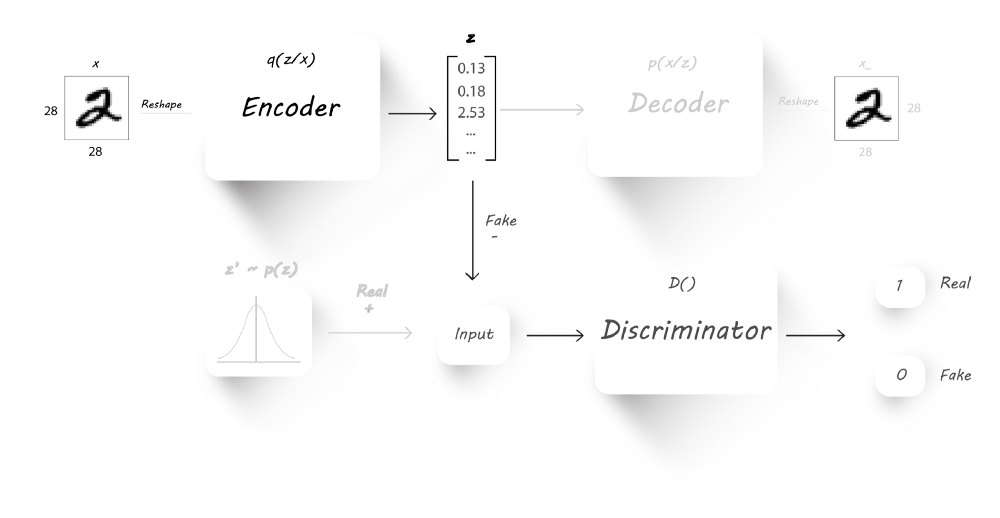
模型
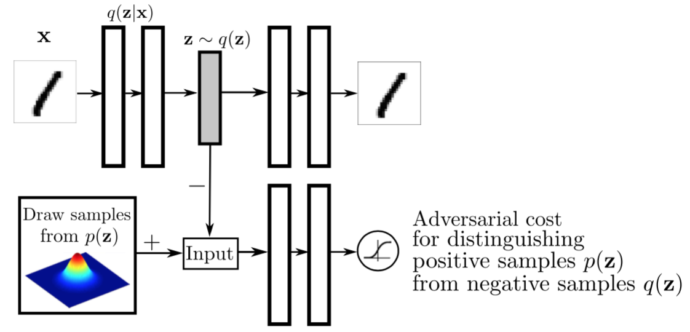

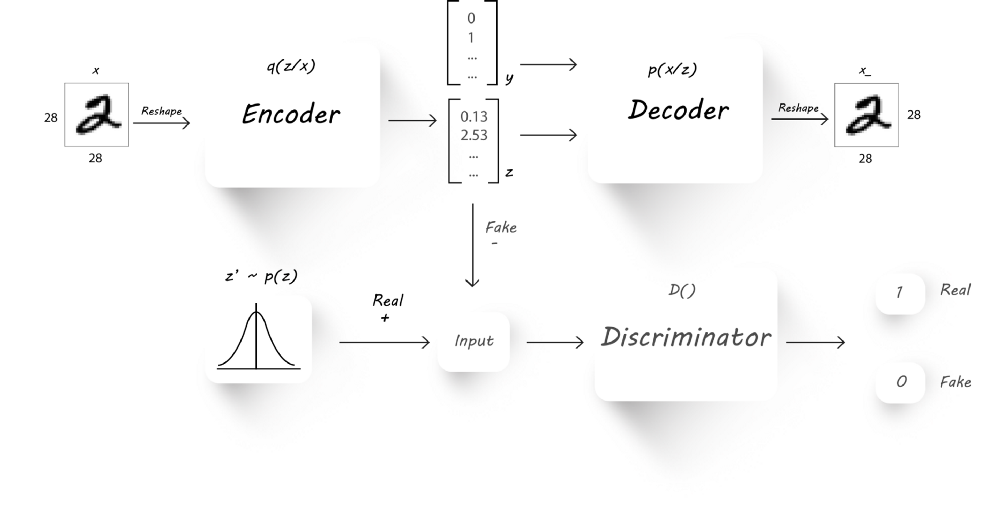
- $x$是输入
- $q(z|x)$是encoder基于输入$x$的输出
- $z$是潜在码,同时也是一个假输入,从$q(z|x)$中采样得到
- $z’$是采样自想要的分布,作为真实输入
- $p(x|z)$是基于$z$的decoder输入
- $x_$是重构图像
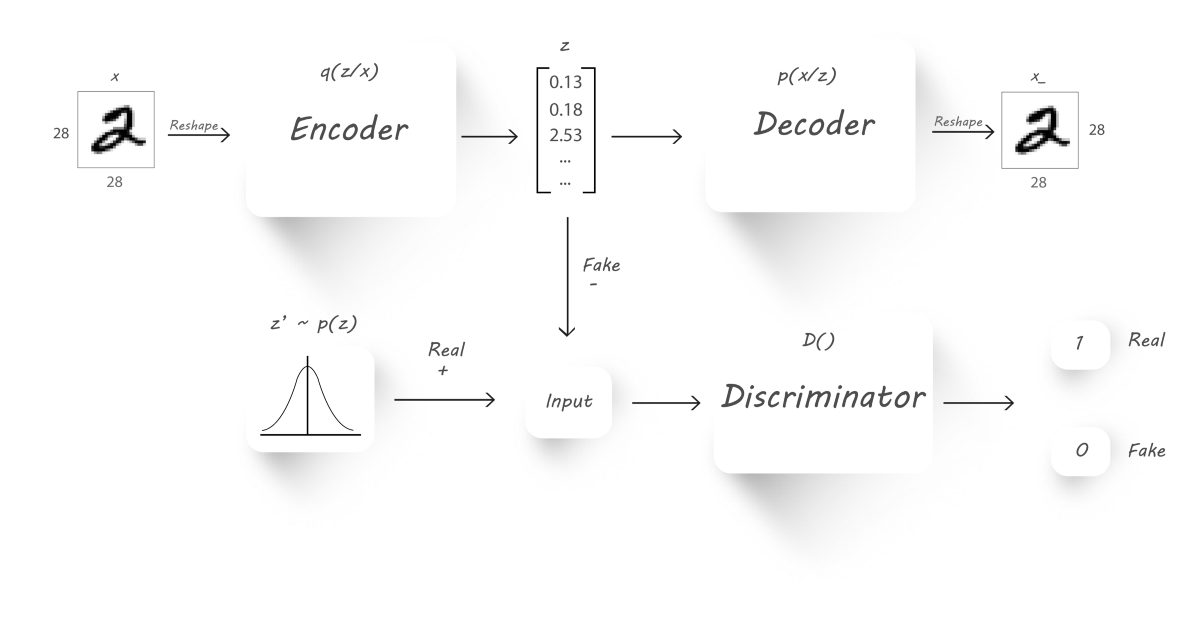
我们的主要目的是迫使encoder的输出逼近一个先验分布(比如正态分布,gamma分布等)。我们将使用encoder$(q(z|x))$作为生成器,而判别器辨别它的输入是来自于一个先验分布$p(z)$,亦或是来自于encoder的输出$z$,decoder仍然进行图片重构的工作。
训练
AAE的训练分成两个部分:重构阶段和正则化阶段。
训练上述模型,分成两个阶段:一个是对辨别器的训练;另一个是对GAN模型的训练。
对于分辨器,其输入就是真假latent code,输出real概率
对于GAN模型,它需要配合分辨器来完成训练。encoder-decoder产生两个输出:一个是latent code,一个是image,但是我们只需要latent code作为分辨器的输入,从而完成GAN模型的训练。
重构阶段
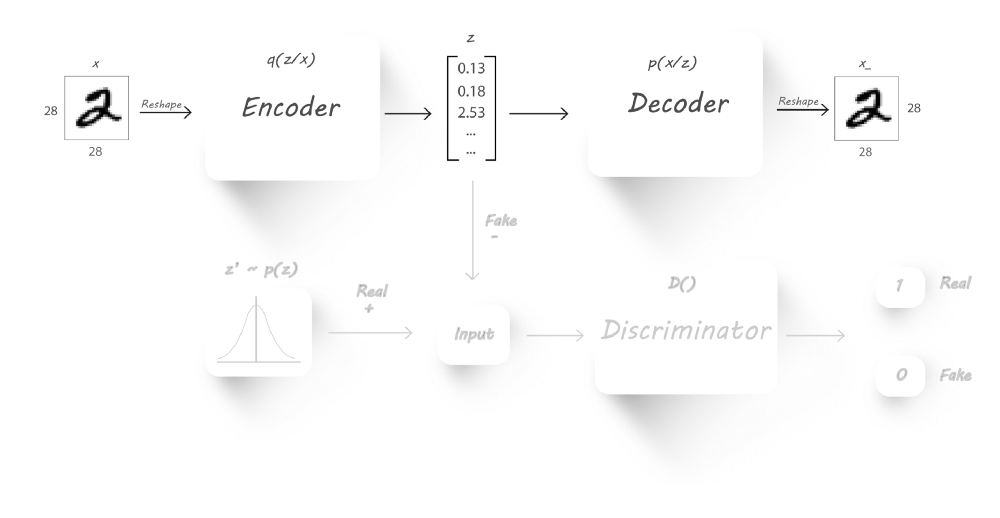
在该阶段,我们需要训练encoder和decoder来最小化重构误差(输入图片与重构图片间的均方误差)。我们将输入传递给encoder,encoder输出一个潜在码;随后,我们将该潜在码送入decoder从而得到一张重构图像。
正则化阶段
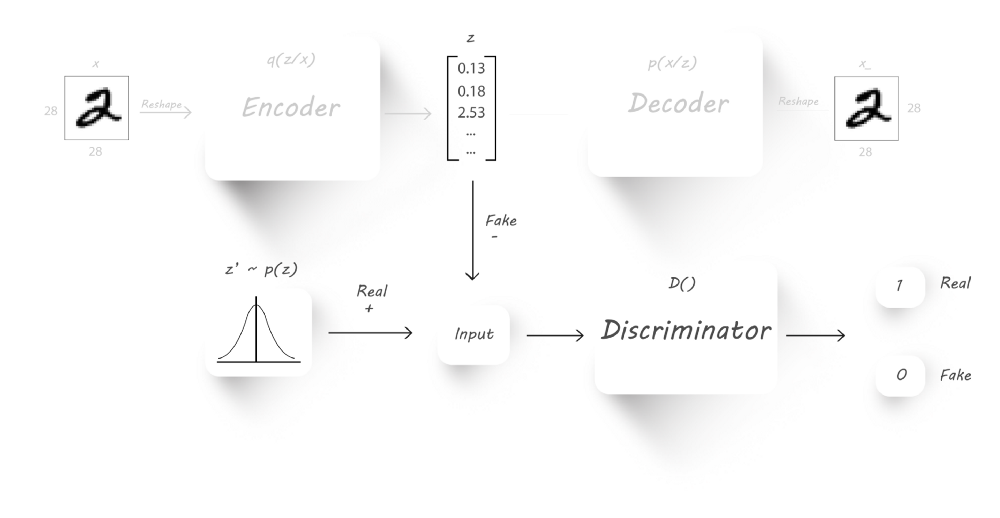
在该阶段,我们训练生成器和辨别器,我们将encod的输出$z$和随机采样$z’$(来自于想要的分布)作为输入来训练辨别器,这样辨别器就会返回1如果输入是$z’$,而返回0如果输入是$z$。接下来,为了迫使encoder的输出$z$逼近我们想要的分布,我们将encoder的输出作为辨别器的输入,连接encoder和辨别器。
我们固定辨别器的权重参数,固定输入的目标标签为1,然后我们输入一些图像到encoder,并计算辨别器的输出与目标标签间的差异(使用交叉熵损失函数),这个阶段我们只更新encoder的权重参数,这样促使encoder去学习我们想要的分布,使输出服从这个分布。
Python实现
Encoder构造
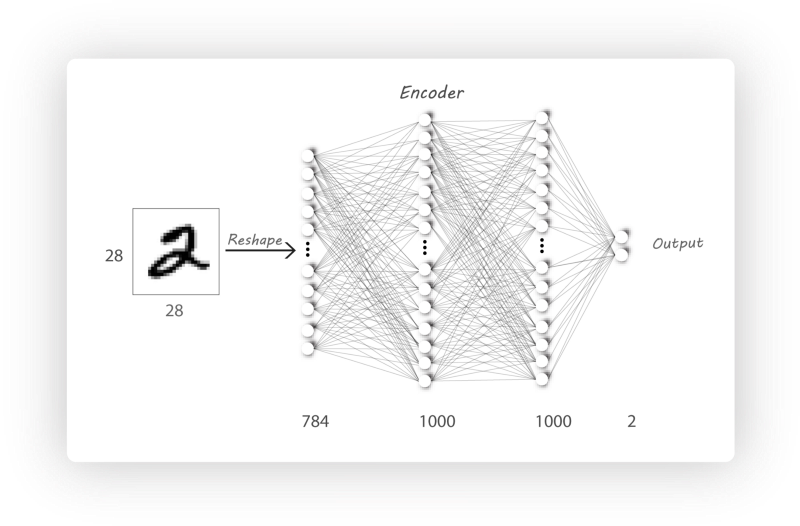
|
|
|
|
Decoder构造
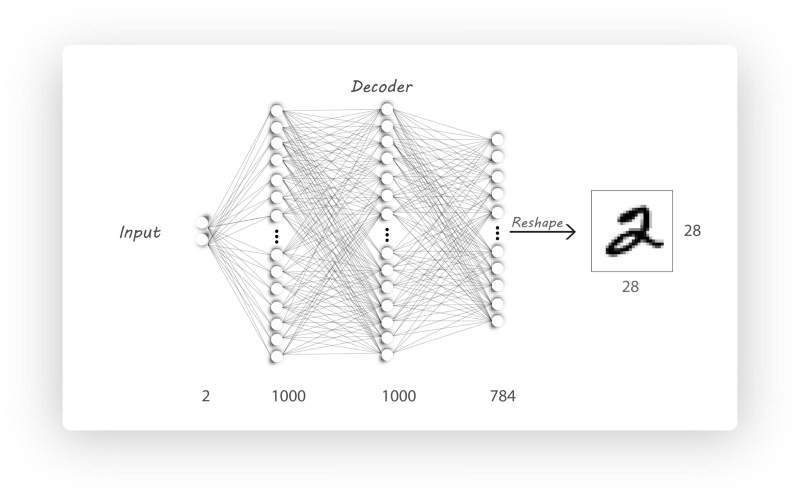
|
|
Discriminator构造
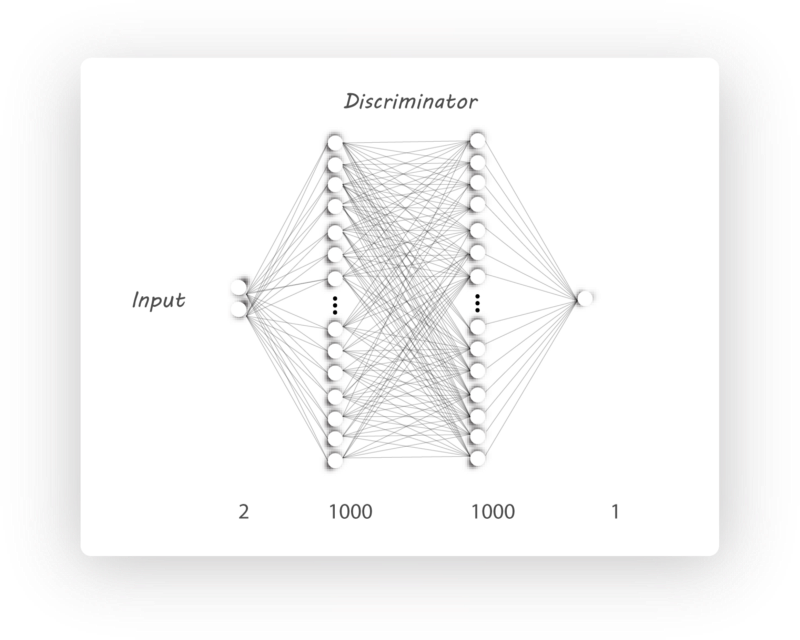
|
|
GAN的构造与编译
|
|
|
|
|
|
监督AAE
Disentanglement of style and content
对于一个写作主题,每一个人写出来的文章都有不同的内容(content)和字体(style)。对于MNIST字体,可以发现它的所有图像都有一样的style,所以我们想要从这个数据集中学习MNIST字体的style。为了更明确content和style的区别,我们有如下图:
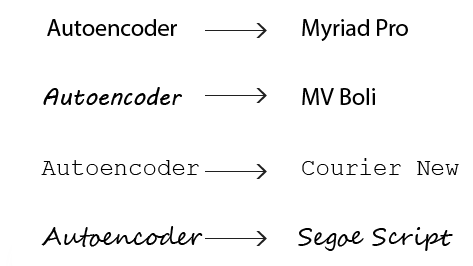
每个文本都有相同的content “Autoencoder”,但是它们的字体是不一样的,现在我们想要从图片中去区分style(Myriad Pro, MV Boil,…)和content,特征分离是表征学习(representation learning)的一个重要内容。
Autoencoder和Adversarial Autoencoder都是无监督学习,因为在训练过程中我们并没有世人任何label信息,但是如果利用图片的label信息则会帮助AAE去提取style信息而不受图片content的影响,这样我们的AAE就变成了一个监督模型。
模型
除了利用latent code作为decoder的输入,我们同时把标签y信息作为另一个输入,decoder利用这两个输入来生成图片。encoder学习图片的style,decoder利用该学习到的style和额外的内容信息y来重构输入图片
相比较于无监督AAE,唯一的区别就是decoder的输入:
- 来自encoder的latent code
- 图像标签的独热表示
训练
重构阶段
我们将输入图像送入encoder得到输出latent codez,然后将z和图像标签y串接起来成为一个更大的输入送入decoder。我们训练AE使最小化图片重构损失
正则化阶段
与无监督 AAE一样。
Python实现
Decoder
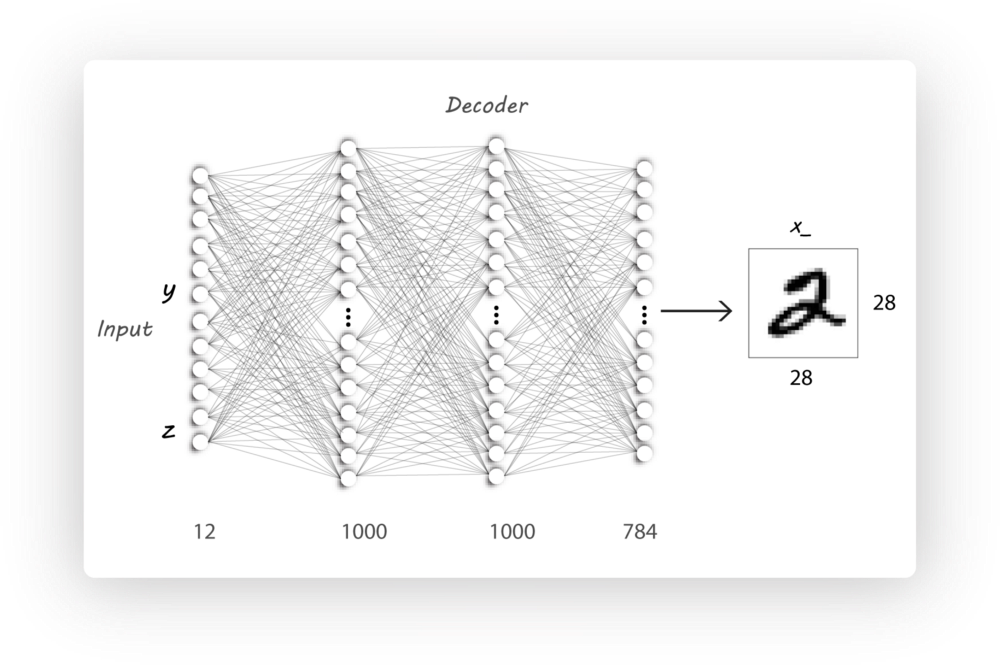
MNIST的图像总共有10类,则y的独热向量长度就是10,laten code的长度是2,则decoder的输入长度是(10+2)
|
|
GAN分类器
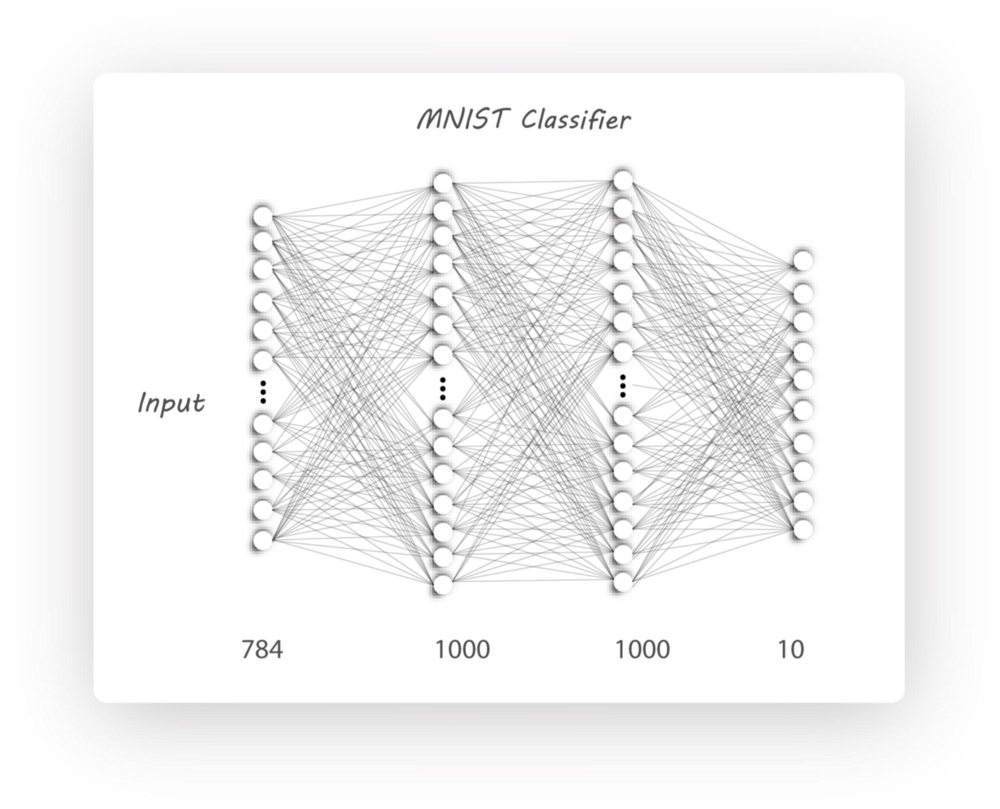
本节我们将介绍如何利用encoder对MNIST手写体进行分类,并与传统的神经网络分类器(NN)比较,为保证实验公平性,encoder和NN使用相同的结构。
我们首先介绍传统的NN分类器,如下图所示,
那么我们如何将encoder改造成为一个分类器呢?实际上,encoder分类器不仅能够提升分类准确率,还可以减少数据维度,从图片中分离内容和风格,我们的模型如下:
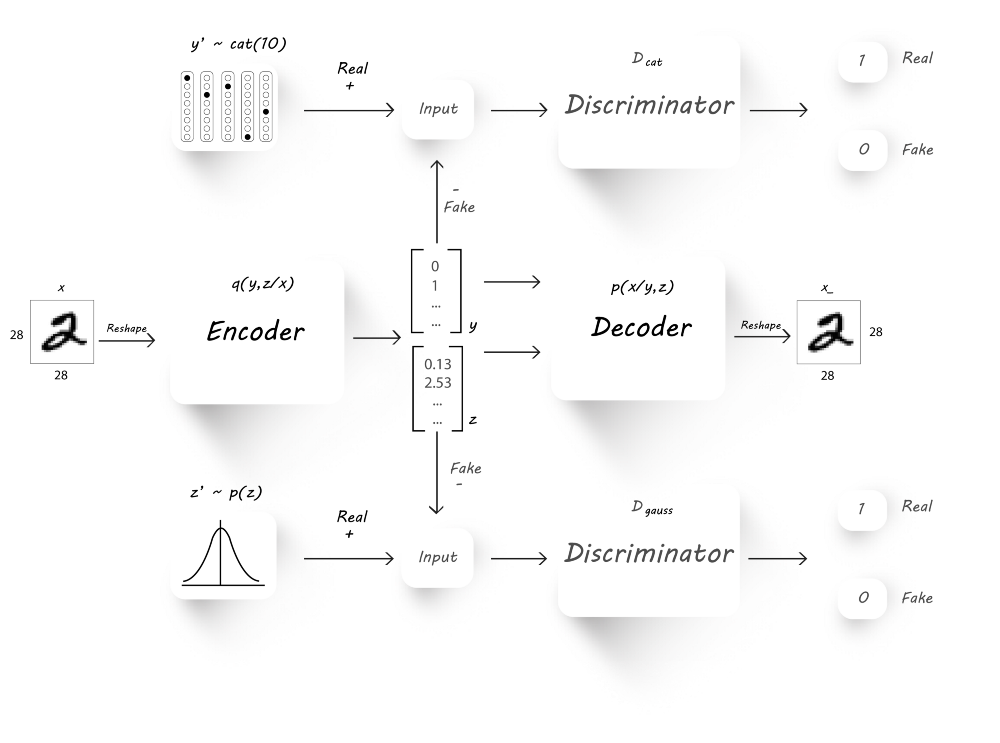
可以看到,我们增加了额外的discriminator($D_{cat}$),该分类器以对抗的方式与encoder一起训练,从而迫使encoder产生10维的独热分类向量
在AAE的基础上对encoder作了修改,此时encoder有两个输出:latent code(z)和classification(y),由于有10个类,则y为10维向量,而z的维度由用户决定。
图片重构阶段
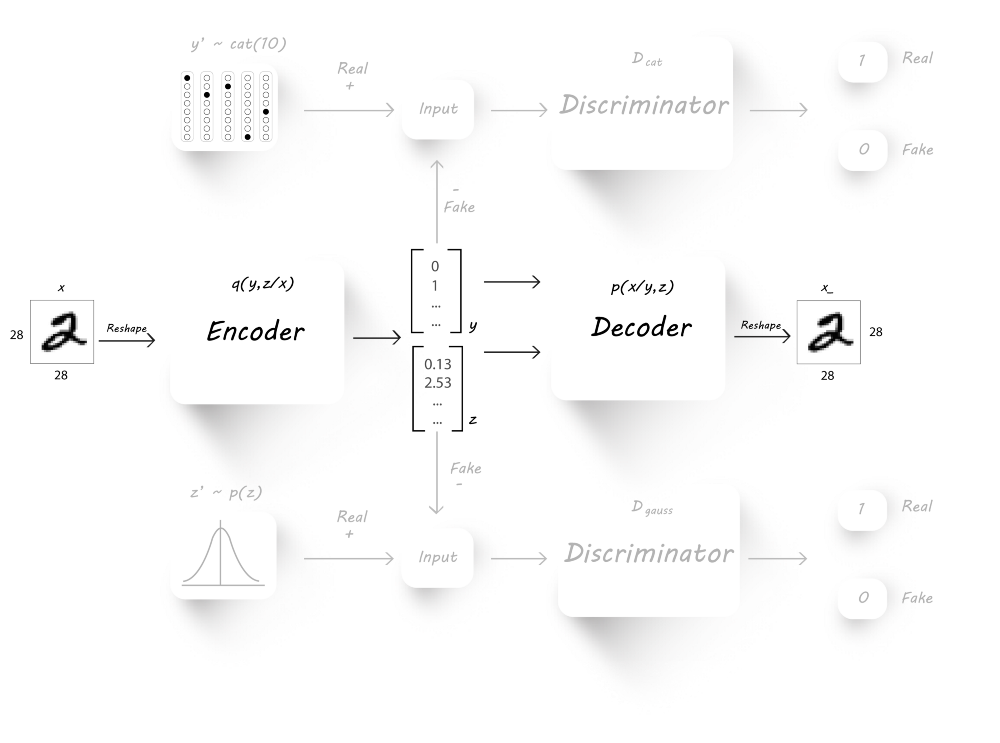
该阶段我们欲使生成的图片逼近我们的真实图片,所以我们使用MSE(mean squared error)来衡量输入图片与输出图片间的差异。
正则化阶段
该阶段由两个部分组成:$D_{cat}$和$D_{gauss}$的训练
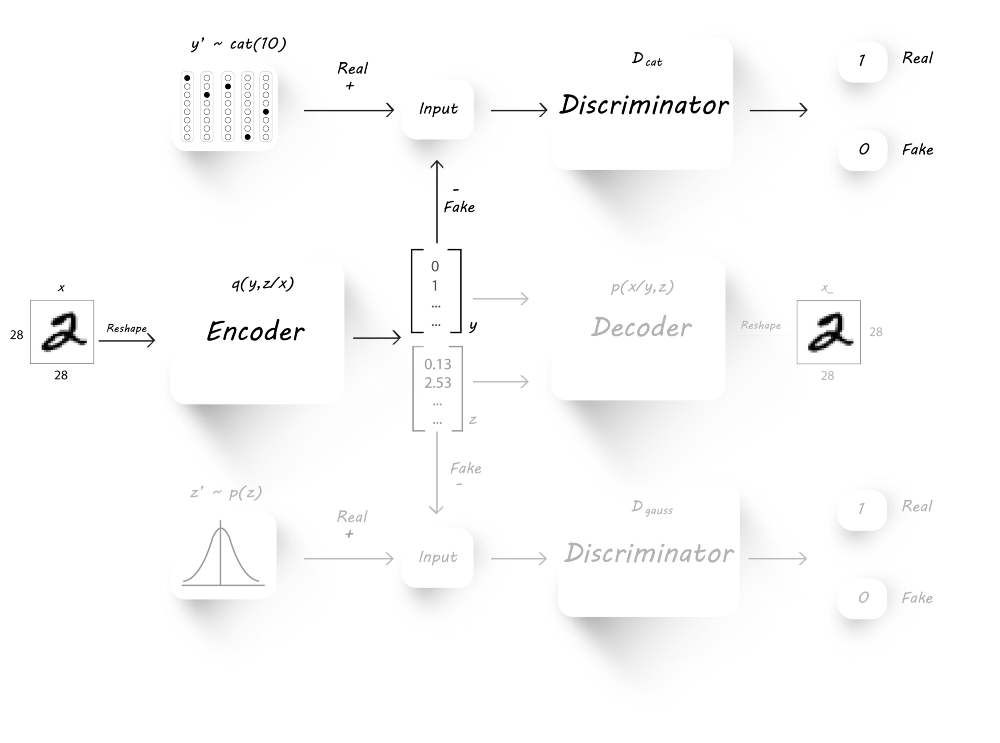
我们首先训练discriminator D_cat来辨别真实的分类标签$y^{‘}$和encoder生成的分类标签$y$。为此,我们将图片作为encoder的输入取产生$y$和$z$,然后将生成的$y$和真实的$y^{‘}$用于discriminator的训练。最后,我们固定分辨器的参数,并设置目标为1,训练encoder来欺骗分辨器。
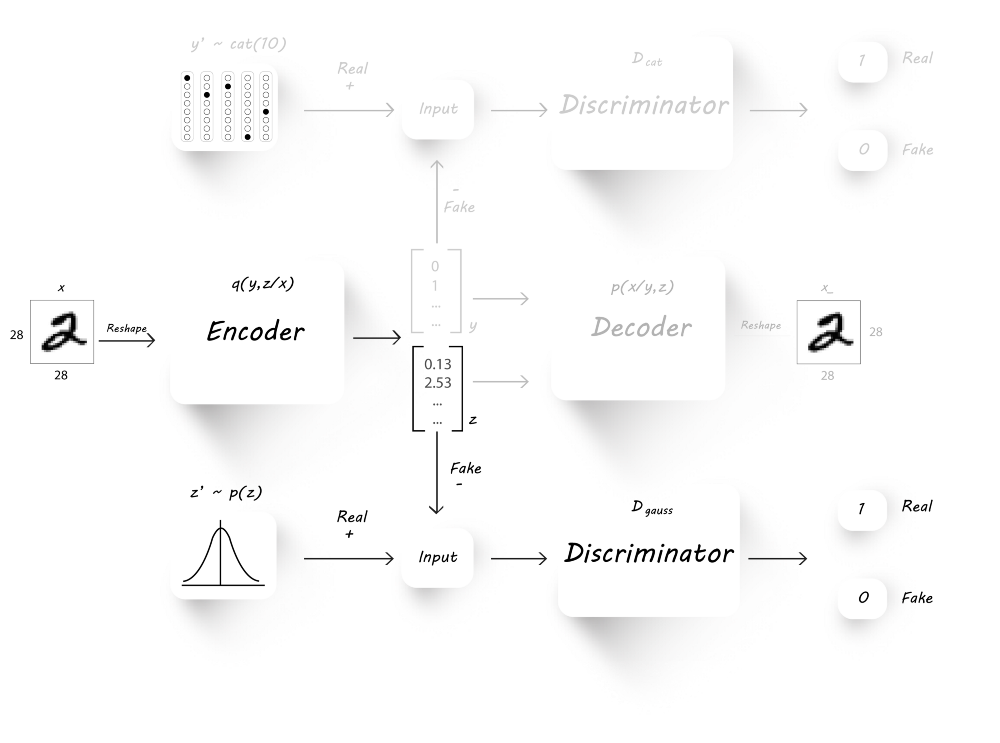
同样的,为了生成具有高斯分布的latent code(z),我们还需要训练分辨器$D_{gauss}$。
半监督分类器阶段
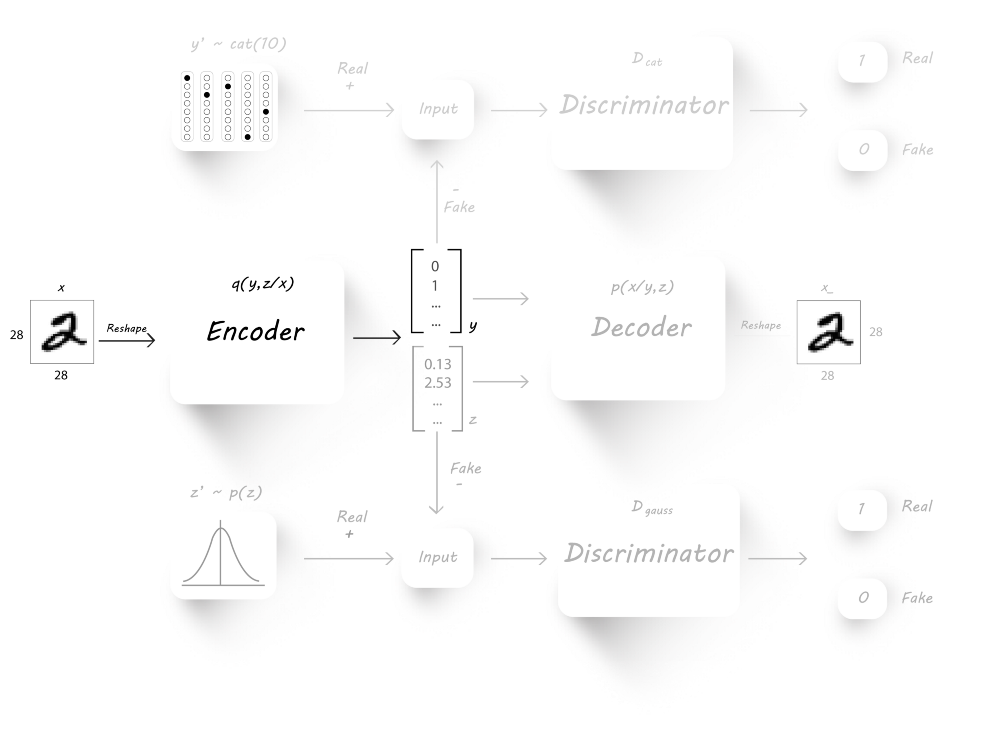
最终我们训练encoder来对手写体数字进行分类,目的是最小化生成的分类标签与真实的标签的交叉熵。
Python实现
Encoder
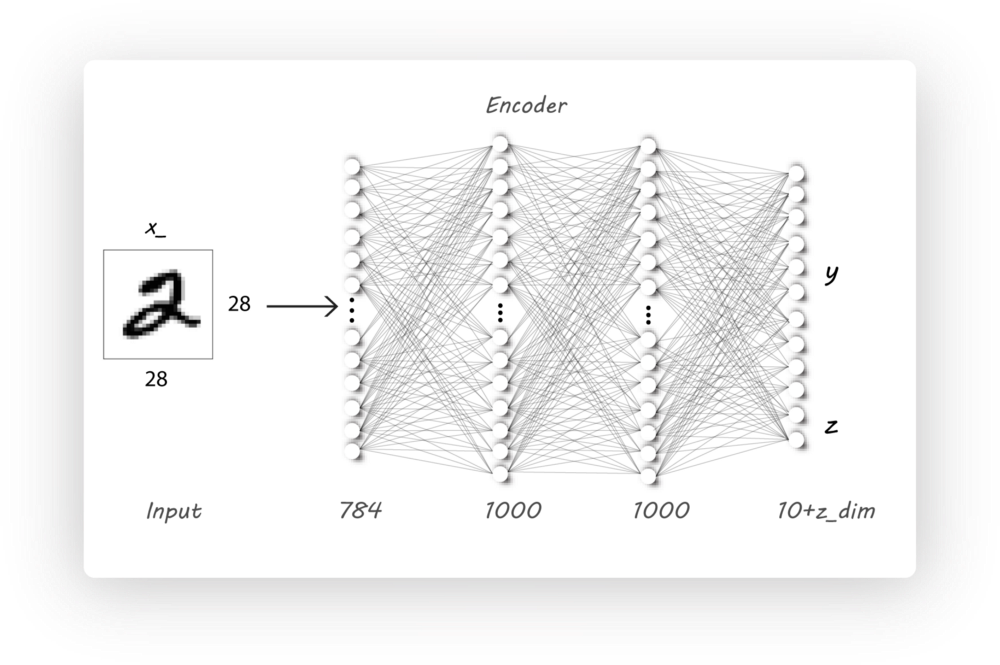
在原始encoder的基础上,只需要需改encoder的输出维度,增加对分类标签的输出
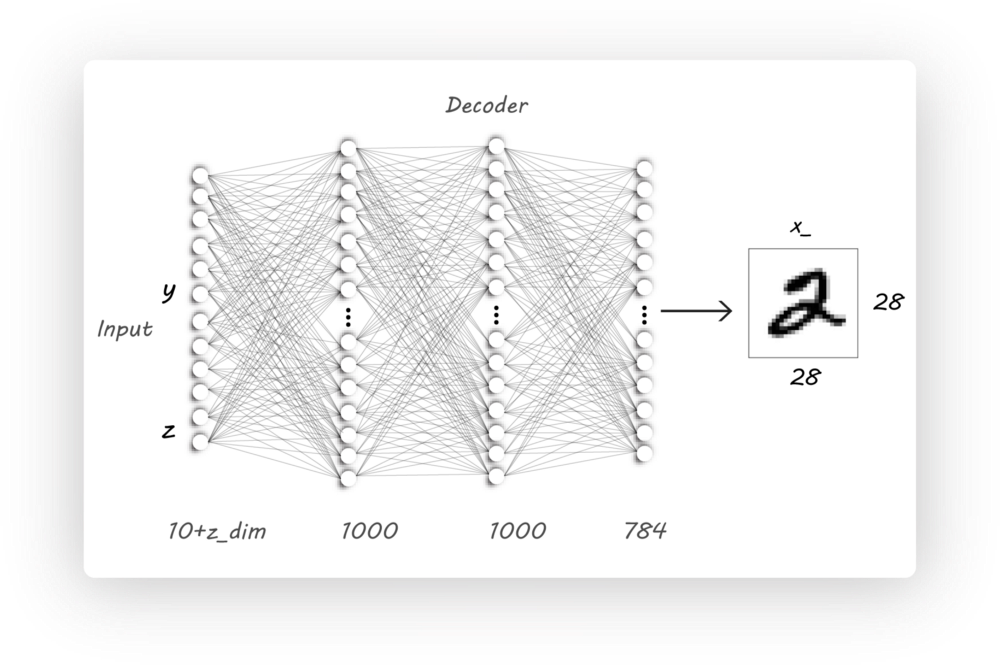
Decoder
Discriminator
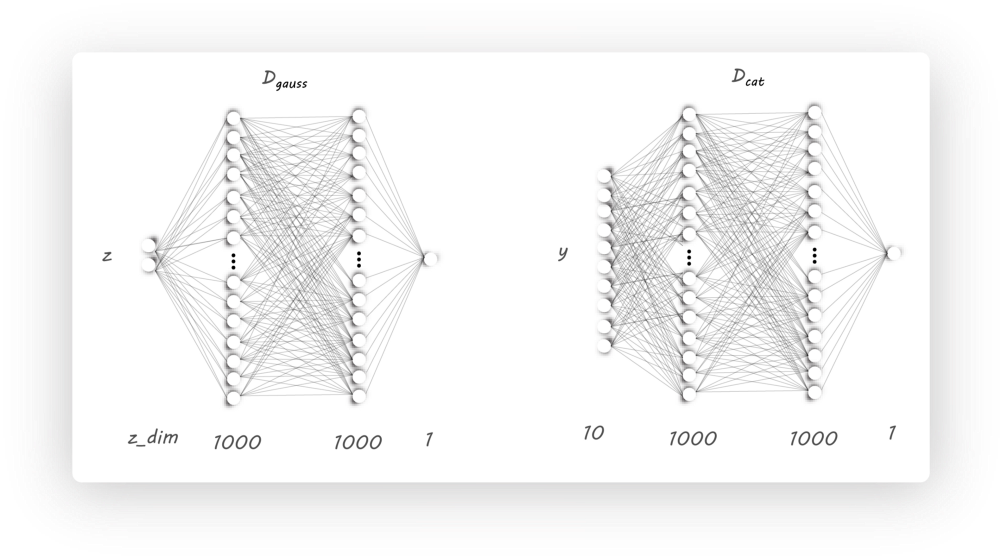
我们需要两个分辨器,它们除了输入维度不同,其他是一样的
CVAE-GAN
《 CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training》