我们之前介绍了GAN模型,在本章中,将介绍一些GAN的变体模型。
CODE in TENSORFLOW summary CODE in KERAS
原始的GAN模型存在着无约束、不可控、噪声信号z很难解释等问,近年来,在原始GAN模型的基础上衍生出了很多种模型,如:条——CGAN、卷积——DCGAN等等
DCGAN
DCGAN的原理和GAN是一样的,它只是把上述的G和D换成了两个卷积神经网络(CNN)。但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
- 取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
- 在D和G中均使用batch normalization
- 去掉FC层,使网络变为全卷积网络
- G网络中使用ReLU作为激活函数,最后一层使用tanh
- D网络中使用LeakyReLU作为激活函数
DCGAN极大的提升了GAN训练的稳定性以及生成结果质量。Ref

DCGAN的生成器网络结构如上图所示,相较原始的GAN,DCGAN几乎完全使用了卷积层代替全链接层,判别器几乎是和生成器对称的,从上图中我们可以看到,整个网络没有pooling层和上采样层的存在,实际上是使用了带步长(fractional-strided)的卷积代替了上采样,以增加训练的稳定性。
Experiment Settings



LS-GAN
最小二乘GAN,在gan的基础上将目标函数变成一个平方误差。实现上直接在gan的基础上修改loss函数

|
|
Conditional GAN
生成对抗网络:Generative Adversarial Networks,通过generator和discriminator的对抗学习,最终可以得到一个与real data分布一致的fake data,但是由于generator的输入z是一个连续的噪声信号,并且没有任何约束,我们很难通过控制z中某数的大小变化让生成的图像发生变化。
GAN中输入是随机的数据,没有太多意义,那么我们很自然的会想到能否用输入改成一个有意义的数据,最简单的就是数字字体生成,能否输入一个数字,然后输出对应的字体。这就是CGAN要做的事。

To include conditional constrain into the cycleGAN network, the adversarial
loss is modified to include the conditional feature vector as part of the input of the generator and
discriminator
在生成器模型中,条件变量y实际上是作为一个额外的输入层(additional input layer),它与生成器的噪声输入p(z)组合形成了一个联合的隐层表达;在判别器模型中,y与真实数据x也是作为输入,并输入到一个判别函数当中。实际上就是将z和x分别于y进行concat,分别作为生成器和判别器的输入,再来进行训练。

训练方式几乎就是不变的,但是从GAN的无监督变成了有监督。只是大家可以看到,这里和传统的图像分类这样的任务正好反过来了,图像分类是输入图片,然后对图像进行分类,而这里是输入分类,要反过来输出图像。
Experiment Settings


Info-GAN
REF1 REF2 GOTTA CODE in KERAS to-do
有了CGAN,我们可以有一个单一输入y,然后通过调整z输出不同的图像。但是CGAN是有监督的,我们需要指定y。那么有没有可能实现无监督的CGAN?这个想法本身就比较疯狂,要实现无监督的CGAN,意味着需要让神经网络不但通过学习提取了特征,还需要把特征表达出来。对于MNIST,如何通过无监督学习让神经网络知道你输入y=2时就输出2的字体?或者用一个连续的值来调整字的粗细,方向?
怎么做呢?作者引入了信息论的知识,也就是mutual information互信息。作者的思路就是G网络的输入除了z之外同样类似CGAN输入一个c变量,这个变量一开始神经网络并不知道是什么含义,但是没关系,我们希望c与G网络输出的x之间的互信息最大化,也就是让神经网络自己去训练c与输出之间的关系。
为了引入c,作者利用互信息来对c进行约束,这是因为如果c对于生成数据G(z,c)具有可解释性,那么c和G(z,c)应该具有高度相关性,即互信息大,而如果是无约束的话,那么它们之间没有特定的关系,即互信息接近于0。因此我们希望c与G(z,c)的互信息I(c;G(z,c))越大越好,mutual information在文章中定义如下:

基于I,整个GAN的训练目标变成:

- 超参数$\lambda$设置为1
- 相当于在原始gan模型上加了一个互信息的正则化项
- 对于c,如果是categorical latent code,可以使用softmax的非线性输出来代表Q(c|x);如果是continuous latent code,可以使用高斯分布来表示。
在最后实现的时候,infoGAN可以看成三个网络:(1)生成网络$x=G(c,z)$;(2)判别真伪网络$y_1=D_1(x)$;(3)判别类别$c$网络$y_2=D_2(x)$(当$c$代表类别信息的时候,网络最后一层是softmax层,且$D_1,D_2$共享网络参数,除了网络的最后一层外);

相比CGAN,InfoGAN在网络上做了一定改变:
(1)D网络的输入只有x,不加c。
(2)Q网络和D网络共享同一个网络,只是到最后一层独立输出。

Experiment Setup


AC-GAN

Generator Input [ noise , label ]
|
|
Discriminator Output [ real/fake , prediction label ]
|
|
Experiment setup

Context-GAN
WGAN
限制discriminator的权重范围$[-0.01,0.01]$
|
|
损失函数
|
|
ground-truth
|
|
GAN_IN_KERAS
构造网络
虽然训练的时候是基于batch大小,但是在设计网络的时候,考虑的是只训练一个样本的网络,Keras有两种形式设置一个神经网络,Model和Sequential。
|
|
损失函数
|
|
训练
一般我们先训练discriminator,它的输入正常情况下是真假图片,真图片来自于训练集,假图片来自于generator输出,我们利用generator模型的prediction函数生成
|
|
这样我们就有了真假图片,就可以训练了,函数是model_name.train_on_batch(x,y),其中$x$就是神经网络的训练集输入,$y$是训练集的ground-truth,看discriminator的输出。
训练discriminator时,它的输入就是一张图片,输出就是真假概率,所以
|
|
训练generate模型,则输入是noise,x = np.random.uniform(0,1,size=(batch_size,100)),它的ground_truth是y=np.ones(shape=(batch_size,1))。
|
|
如果是cgan或者info-gan,那么会有额外的输入和输出,如下图:
这是info-gan,可以看到,在gan基础上有了一个额外输入$c(latent)$,有了一个额外的输出$c$。所以generator的input是x = np.concatenate( z , c ),输出是y = ( f_r_label , c ) ,每一个输出都需要一个ground-truth,所以generator的训练代码:
DRAW: A Recurrent Neural Network For Image Generation
paper tensorflow 2015 - 800citation ref
the DRAW network is a generative model of
images in the variational auto-encoder framework that decomposes image formation into multiple
stages of additions to a canvas matrix. The DRAW paper assumes an LSTM based generative model
of these sequential drawing actions which is more general than our model. In practice, these drawing
actions seem to progressively refine an initially blurry region of an image to be sharper.
Pix2pix
pix2pix是基于条件对抗生成网络来学习从输入图像到输出图像的映射。
生成器
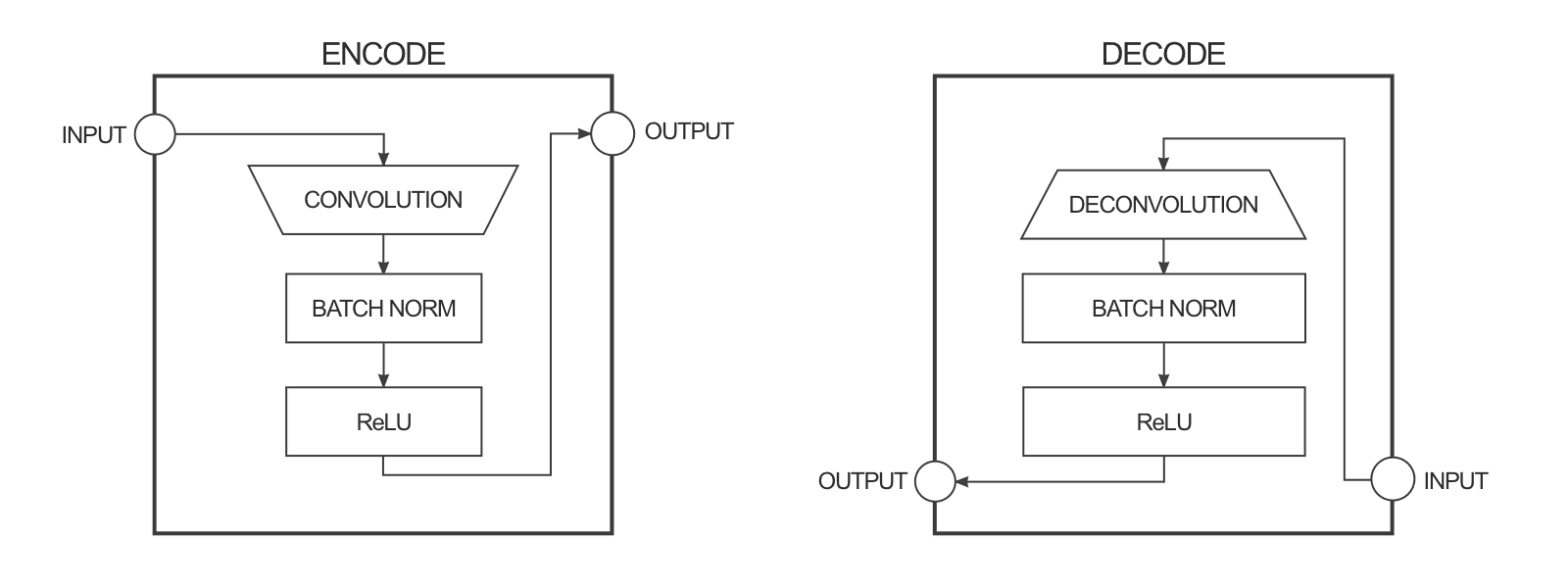
生成器的目标就是将输入的图像转换为目标图像,利用编码-解码器的架构来实现。
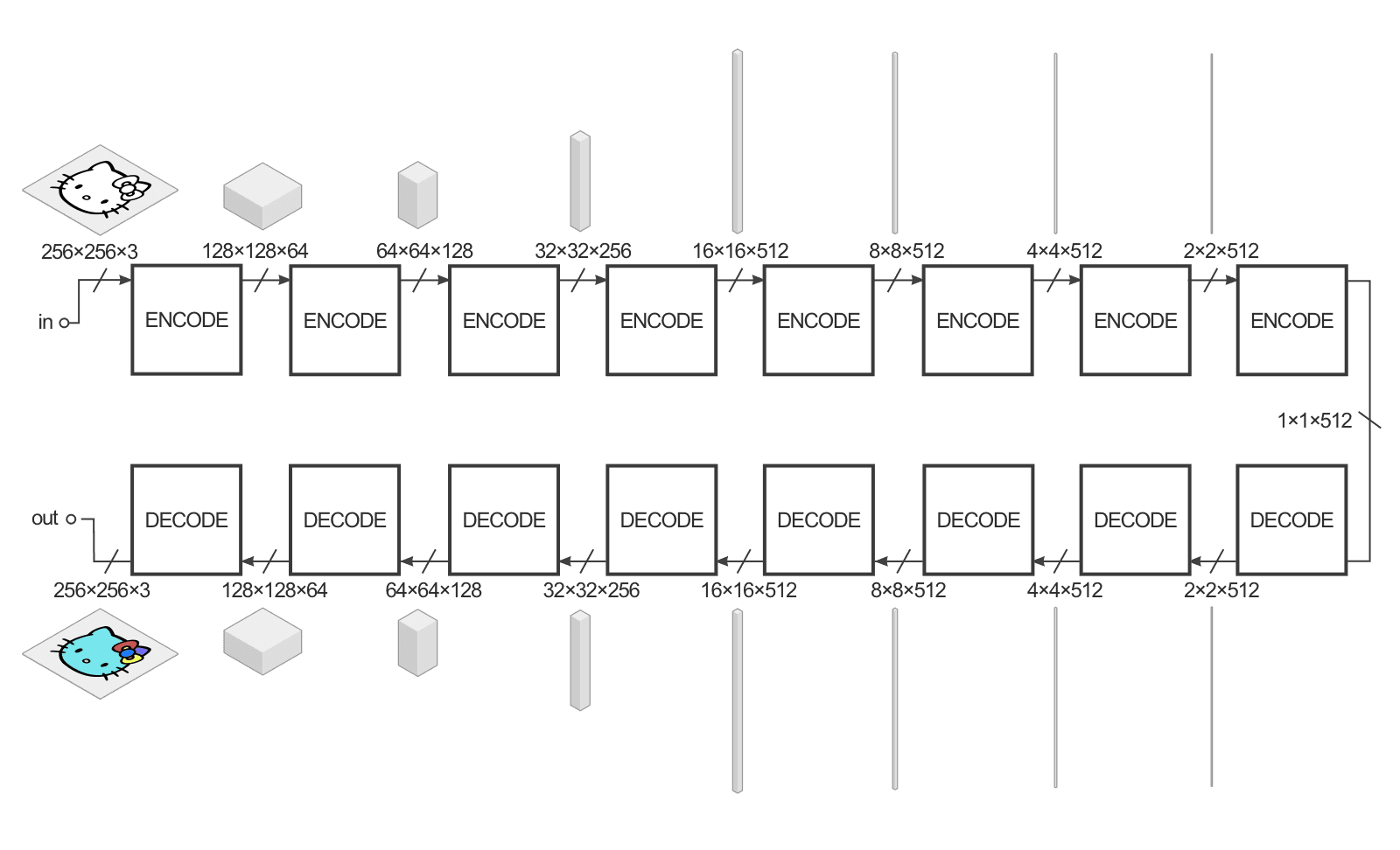
输入图像是256*256大小3种颜色通道的图像(红、绿、蓝通道,对于黑白图,这三个通道的数值相等)。生成器接收输入,并将它用一系列编码器(卷积+激活函数)简化成更小的表示(representation)。这样做的基本想法是我们用最终的编码层可以得到一种对数据更高层次(抽象)的表达。解码器层呢主要做了相反的操作(反卷积deconvolution+激活函数),并将编码层的动作反过来。
为了提高这种图像到图像转换的效率,作者用了一种称为U-Net的方法而不是编码-解码器方法。它们本来是一回事,但是U-Net引入了所谓的“跳跃链接”,以便将编码器层和解码器层直接相连,这种跳跃链接可以为网络提供一种省略编码/解码部分的选择,从而当网络真的用不到它们的时候,处理效率就会很快了。
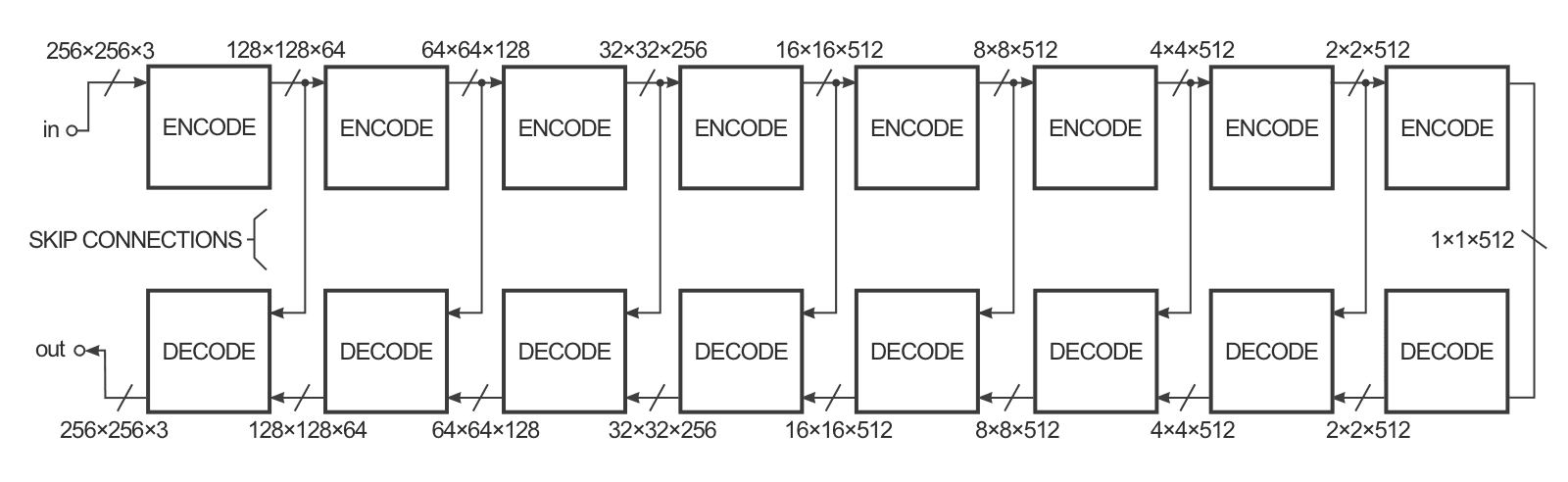
U-Net网络结构
辨别器
对比发现,生成器和辨别器的输入是不同的:前者只有一张图片作为输入,后者有两张图片作为输入,辨别器的输出是一个30*30的图像,每一个像素都是0~1的数值,代表了这一部分与目标图像比起来有多像。在pix2pix的执行中,这30*30图像中的每一个像素都对应了输入图像的70*70个块(patch,这些patch会有很多重叠,因为输入图像大小是256*256)。这种架构称为“PatchGAN”。

损失函数
生成器
除了辨别器判断生成图片的真假损失
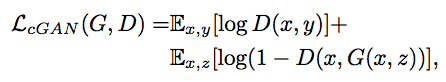
还有$L_1$损失来衡量生成图片的优劣。
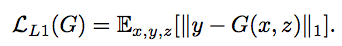
判别器
在损失函数中,L1被添加进来来保证输入和输出的共性。这就启发出了一个观点,那就是图像的变形分为两种,局部的和全局的。既然L1可以防止全局的变形。那么只要让D去保证局部能够精准即可。于是,Pix2Pix中的D被实现为Patch-D,D区分图像中的每个$N*N$大小的补丁是真是假。
Pix2PixHD
Coupled-GAN
Introduction
AAE是一种学习数据分布$P(X)$的方法,Conditional GAN则学习数据的条件分布$P(X|c)$,而Coupled-GAN意在学习数据的联合分布$P(X_1,X_2)$,其中$X_1, X_2$是来自不同域的,比如同一个场景的图片但是一个是彩色图片,一个是深度图片;又或者同一张脸的不同表情(笑和不笑)。
Coupled-GAN是从数据的边缘分布$x_1 \sim P(X_1)$和$x_2 \sim P(X_2)$采样,来学习数据的联合分布,而实现这个的技巧是权值共享。我们认为数据的高层级表征是共享的,故我们强制网络共享部分层的权重,这样CoGAN会趋近学习到两种域数据的共同表征,也就是它们的联合分布。
但是,网络共享哪些层的权重呢?我们知道,神经网络在进行分类任务时,是从下到上的方式学习数据的特征,也即是说从低层级特征到高层级特征。低层级特征过于细致,不够泛化,它们往往捕捉图片的厚度,色彩饱和度等特征;而高层级特征能够学习到数据更为抽象的特征,比如“鸟”,“狗”,忽略图片色彩厚度等细节,所以我们强制神经网络的处理高层级的层共享参数。
对discriminator来说,它的共享层应为最后几层;而对generator来说,它的共享层应该是前面几层,因为生成器的工作方式是从抽象特征生成具体图像。
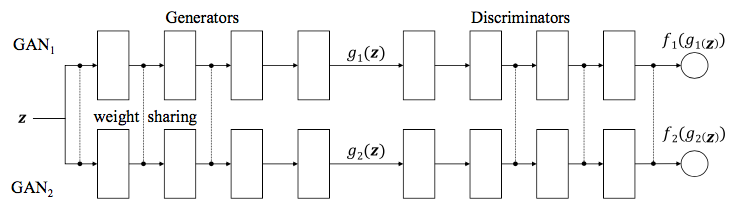
LOSS FUNC
只使用了GAN损失。
Application
Digit Rotation
生成MNIST手写体数字图片相对应的90度旋转图片。两个数据域分别是MNIST图片和被旋转90的手写数字图片。

Digit Edge
生成手写体数字相应的边缘图片。

Negative Image
生成图像的反图像。PIL-Negative Img

Color & Depth Images
Domain数据迁移
CycleGAN,DualGAN,DiscoGAN