聚类
在无监督学习中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据内在性质及规律,此类学习中研究最多、应用最广的是“聚类(Clustering)”。
聚类试图将数据集中的样本划分为若干个不相交的子集,每个子集称为一个“簇(cluster)”。形式化地说,假定样本集$D=\{x_1,x_2,…,x_m\}$包含$m$个无标记的样本,每个样本$x_i=\{x_i^{1},x_i^{2},…,x_i^{n}\}$是一个$n$维特征向量,则聚类算法将$D$划分为$k$个不相交的簇。
K-means算法
模型
给定样本集$D=\{x_1,x_2,…,x_m\}$,“k均值”算法针对聚类所得到簇划分$C=\{C_1,C_2,…,C_k\}$最小化平方误差:
其中,$u_i=\frac{1}{|C_i|}\sum_{x\in C_i}x$是簇$C_i$的均值向量。上式在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度,E值越小则簇内样本相似度越高。

优缺点
- Cons
- 需要指定k值Selecting the number of clusters with silhouette analysis on KMeans clustering
- 局限于线性边界的划分kernelized k-means
- 数据量大时效率低
Python例子
K-means From Sratch
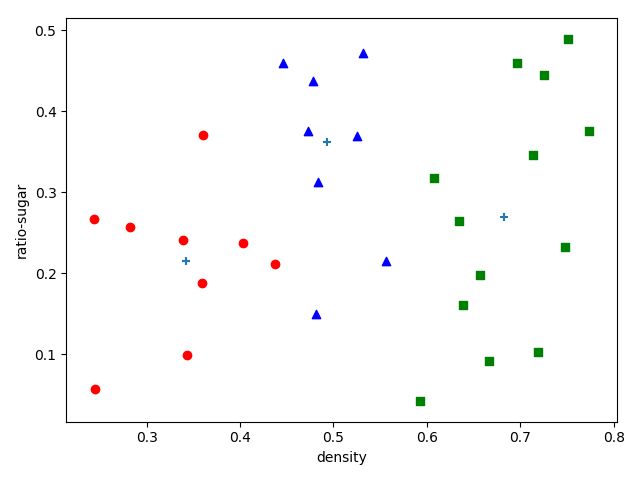
下面我们以一个例子来演示k均值算法的学习过程,数据如下所示:
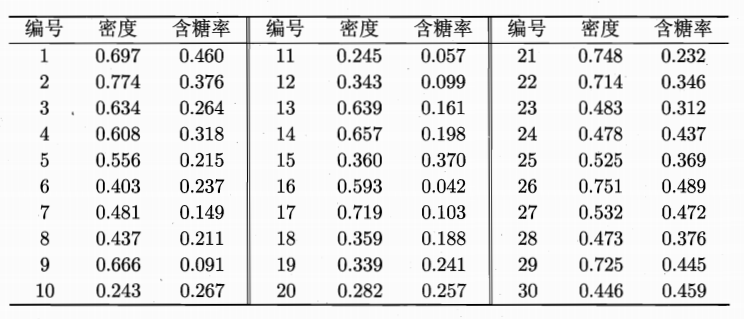
记第$i$个样本称为$x_i$,每个样本包含两个属性“密度”和“含糖率”,属于二值向量。
STEP1:数据读取。
我们使用panda的read_csv()函数读取.csv文件,header=None表示第一行也被读取。
|
|
STEP2:选取k个簇均值
这里我们k设置为3,随机从数据样本中选择3个样本作为初始簇均值向量。
|
|
从上面看到,我们还设置了其他参数,如最大迭代次数10000,self.cluser_number就是k值。
STPE3:处理每一个样本
对每个样本,我们计算它与三个簇均值的欧氏距离,选择距离最小的簇作为该样本的归属簇。
|
|
一旦处理完所有样本之后,我们就要更新每个簇的均值向量了。
|
|
组合在一起之后,我们的clustering更新如下:
|
|
STEP4:每个簇内样本可视化
|
|
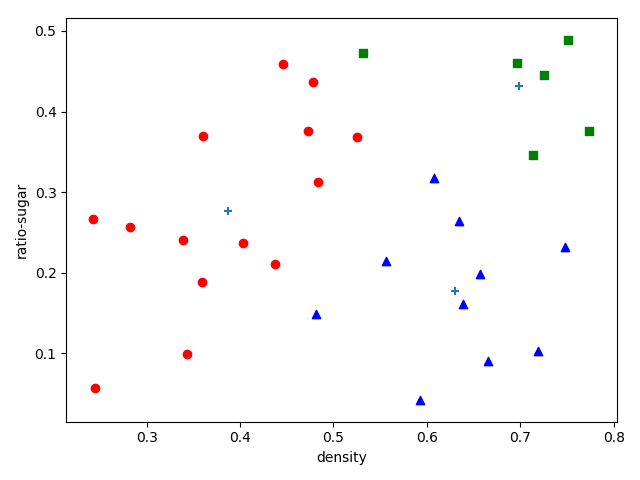
K-means in SKlearn
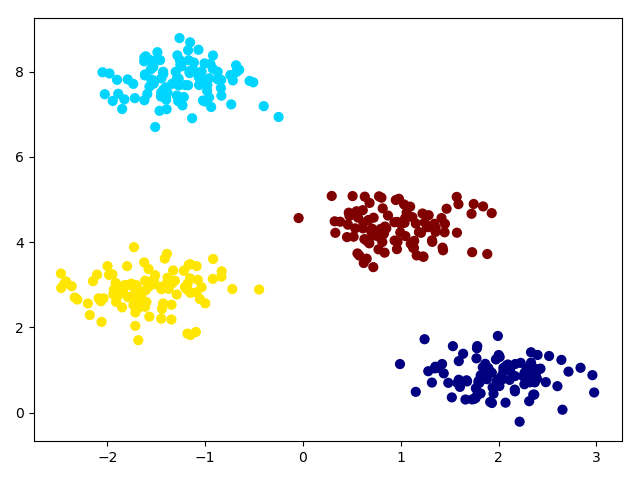
sklearn已经实现了k均值算法,我们直接使用它来解决问题。首先我们先生成4组二维无标签数据样本,
|
|
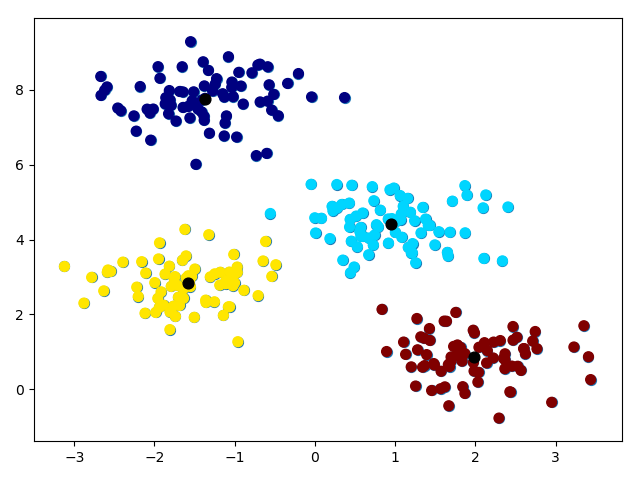
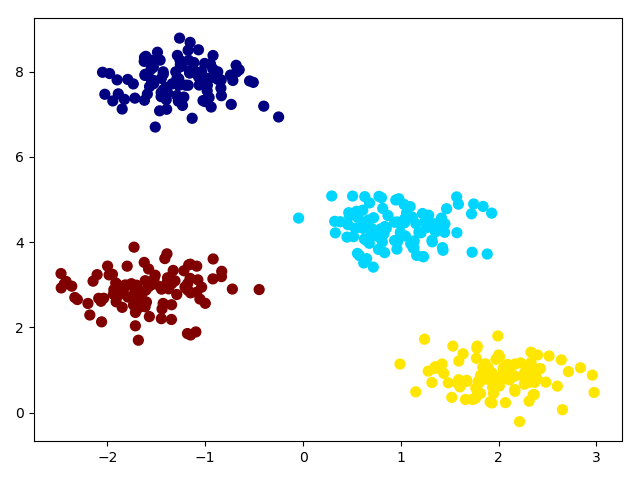
接下来,我们使用sklearn内置k-mean方法对上面的数据聚类
|
|
K-means in Digits Clustering
给定数字图,我们将它分为10个类。
首先我们载入数据,总共是1797个$8\times 8$的图片,这样每个样本就是64个特征。
|
|
k-means for color compression
高斯混合聚类
k-means聚类属于hard assignments,即每一个点一定要被分配到一个类中;但是如果两个真实的簇相互重叠,在重叠区域的点可以同时属于两个类,但是k-means只会分配点到更近的簇中。而高斯混合模型聚类(Gaussian Mixture Models)解决这个问题。我们首先回顾高斯分布,然后介绍高斯混合模型,以及模型求解的方法EM算法。
一元高斯分布的密度函数为:
多元高斯分布的密度函数:
一元高斯分布函数中的$x$是标量,多元高斯分布函数中的$x$是一个向量。
其中$\mu$是$n$维均值向量,$\sum$是$n\times n$的协方差矩阵。
模型
假设数据点来自几个不同的高斯分布,这样所有样本点混合一起,构成了一个高斯混合分布:
该分布共由$k$个混合分布组成,每个混合分布对应一个高斯分布,其中$u_i$与$\sum_i$是第$i$个高斯混合成分的参数,而$\alpha_i>0$为相应的混合系数,$\sum_{i=1}^{k}=1$。
假设样本的生成过程由高斯混合分布给出:首先,根据$\alpha_1, \alpha_2,…,\alpha_k$定义的先验分布选择高斯分布混合成分,其中$\alpha_i$为选择第$i$个混合成分的概率;然后,根据被选中的混合成分的概率密度函数进行采样,从而生成相应的样本。

Python例子
GMM from scratch
同样以上面的西瓜数据集为例,令高斯混合成分的个数$k=3$。算法开始时,假定高斯混合分布的模型参数初始化为:$\alpha_1=\alpha_2=\alpha_3=\frac{1}{3}$, $\sum_1=\sum_2=\sum_3=(\begin{matrix}0.1 & 0.0 \\0.0 & 0.1 \end{matrix})$ , 随机选择$k$个样本点作为初始聚类中心。
|
|
根据多元高斯分布密度函数公式,我们完成密度函数计算:
|
|
E-step: 针对每个样本计算属于各个混合成分的概率
|
|
M-step: 更新高斯分布参数$u$和$\sum_i$, 以及混合系数$\alpha$
|
|
完整代码
|
|
GMM in Sklearn
sklearn内置GMM算法,为了熟悉该方法,我们生成一组400个样本数据,隶属于4个簇:
|
|
GMM给出了分类的置信度,predict_proba返回一个大小为[n_samples,n_clusters]的矩阵,每个元素值反应了样本点属于某个簇的概率大小。这样我们就可以将分类的不确定度可视化,通过使每个点的大小与分类确定度成正比。
|
|
GMM as Density Estimation
除了聚类,高斯混合模型更常用于密度估计,即根据已知的数据样本去拟合该数据的分布,从而生成新的数据,这也使高斯混合模型成为一个生成模型。接下来我们生成一些数据样本,然后利用GMM去拟合该分布。
|
|
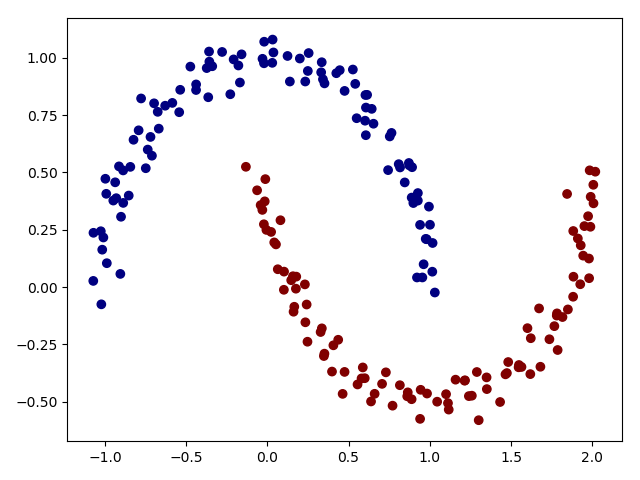
即我们生成的数据是2维度的,如果我们使用2成分的高斯混合模型去聚类:
|
|
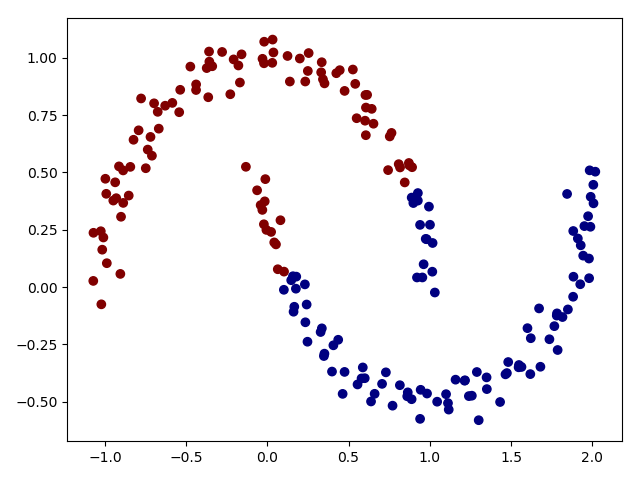
可以看到基于最近聚类的方法在这个例子中是不准确的,但是如果我们多增加几个成分,即成分个数变成16,gmm = GMM(n_components=16).fit(x)
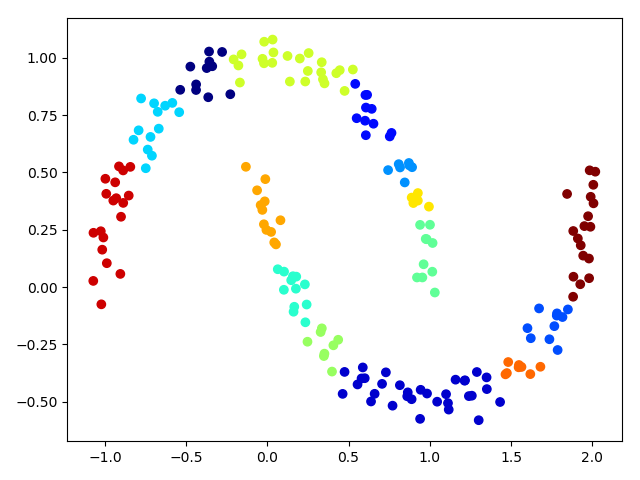
实际上,这16个高斯成分并不是用来数据划分,而是去建模数据整体分布。这是数据的生成模型,即GMM给了如何生成样本数据的模型,比如我们使用该模型去采样500个数据点:
|
|
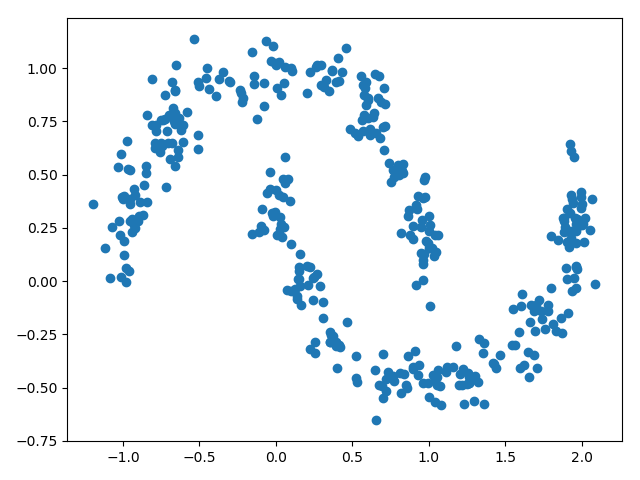
GMM in Data Generation
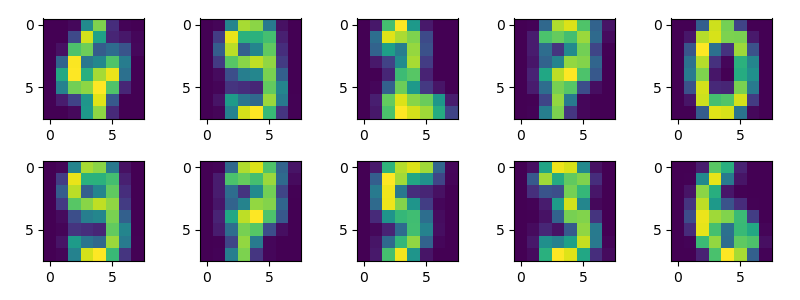
上面的例子简单地介绍了GMM在数据生成的应用,接下来我们介绍如何利用GMM 生成手写体数字。首先,我们先载入手写体数字:
|
|
我们选取前100个数据进行可视化
|
|

现在我们要使用GMM去拟合手写体,但是因为每一张图片的维度是64,对GMM而言,数据维度太高使模型不容易收敛,所以我们使用PCA进行降维。
|
|
最终降维到41,几乎$\frac{1}{3}$无用的信息被去除。接下来我们使用AIC指标来指导我们如何选取最优的成分数目。
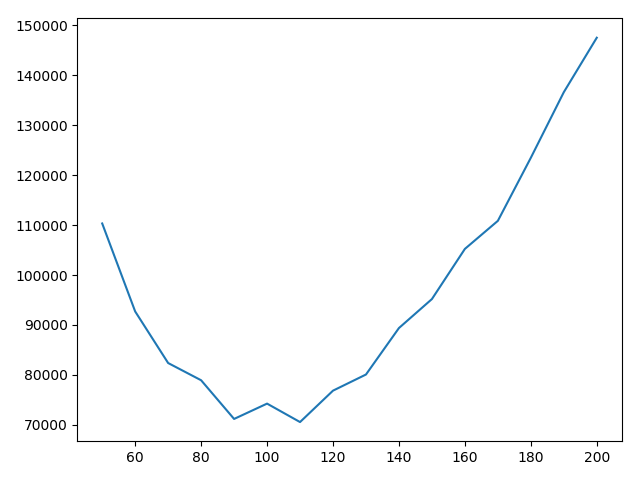
从图像中可以看到高斯成分数目为110是最佳的,所以:
|
|
