机器学习中,在高维情形下出现的数据样本稀疏、距离计算困难等问题,被称为“维数灾难”(curse of dimensionality)。而缓解该问题的一个重要途径是降维(dimension reduction),即通过某种数学变换将原始高维空间转换为一个低维“子空间”(subspace),在这个子空间中样本密度大幅度提高,距离计算也变得更加容易。
之所以可以进行降维,是因为在许多时候,人们观测或者收集到的数据样本虽然是高维的,但是与学习任务相关的也许仅仅是某个低维分布。

成分数目选择
PCA降维一个重要的步骤是预先确定成分数目来描述数据,一种方法是计算cumulative explained variance ratio,
其中,$d$是原始数据维度,$d’$是数据降解之后的维度,$\lambda_i$是第$i$个特征值。
|
|
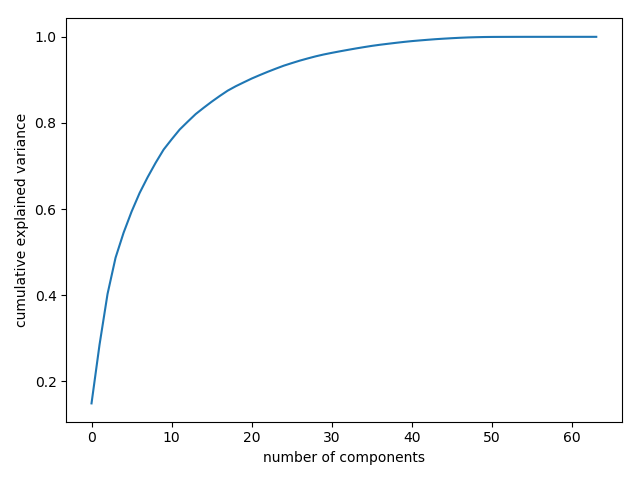
This curve quantifies how much of the total, 64-dimensional variance is contained within the first NN components. For example, we see that with the digits the first 10 components contain approximately 75% of the variance, while you need around 50 components to describe close to 100% of the variance.
Here we see that our two-dimensional projection loses a lot of information (as measured by the explained variance) and that we’d need about 20 components to retain 90% of the variance. Looking at this plot for a high-dimensional dataset can help you understand the level of redundancy present in multiple observations.
|
|
我们利用sklearn中的方法来探索pca,首先生成样本数据:
|
|
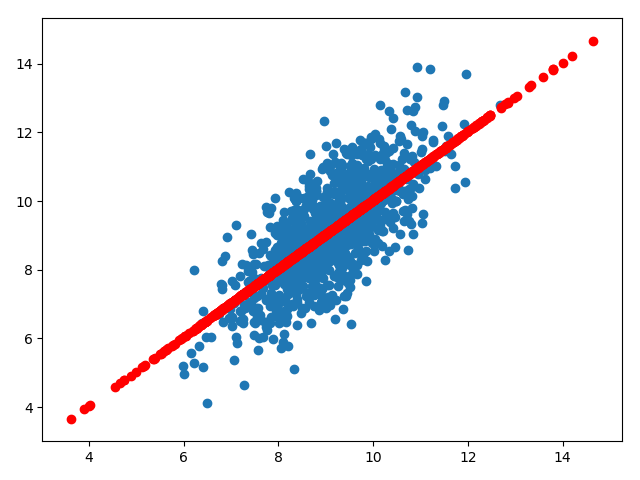
明显的,x和y存在类似线性的关系,但是不像线性回归去建模得到一个从x到y的预测函数,PCA尝试学习x与y的关系,这种关系是由一组特征向量和特征值表示:
|
|
其中pca.components_是特征向量,pca.explained_variance_是特征值。为了了解它们的意义,我们将之可视化:
|
|
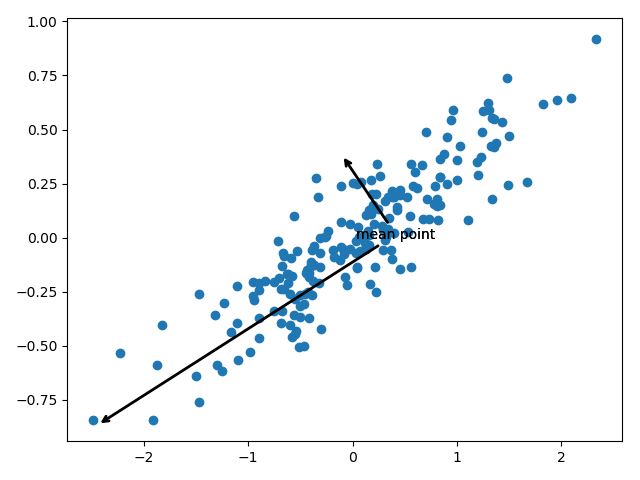
这些向量表征数据的主轴,而向量的长度描述了数据在该方向分布的重要性。
More precisely, it is a measure of the variance of the data when projected onto that axis. The projection of each data point onto the principal axes are the “principal components” of the data.
PCA in Dimension Reducation
在维度削减中,PCA剔除一个或多个最小的主成分,使数据在低维上的映射尽可能保存数据的多样性。
|
|
数据被降维到1维空间,为了更加直观的理解降维效果,我们将降维后的数据还原到初始空间,
|
|
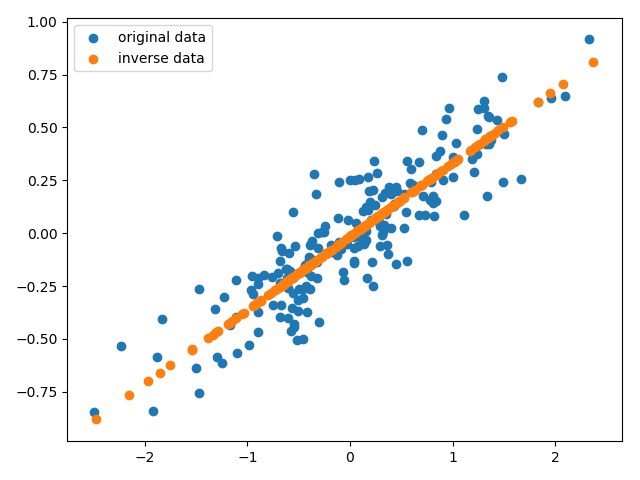
从图中可以看出PCA降维的原理:分布在比较不重要的轴的信息被移除,留下分布在重要轴的信息。
PCA for Visualization
这一次我们使用高维的数据进行可视化,先载入数据:
|
|
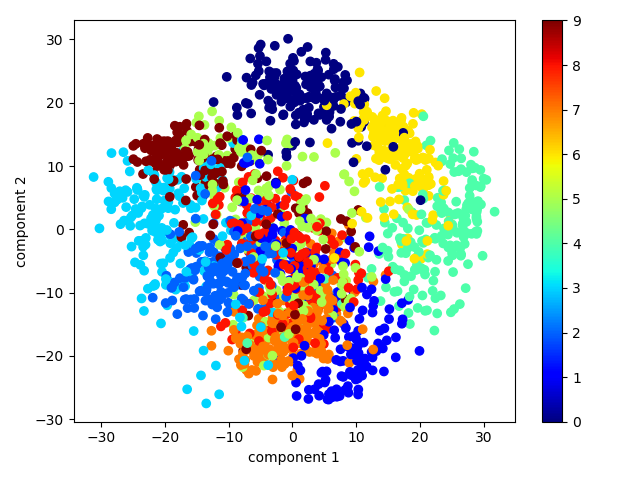
手写体数字是8*8图片,故有64个维度,为了理解这些数据点之间的关系,我们将之降维到平面,即2维空间:
|
|
最终将它们可视化:
|
|
PCA as Noise Filtering
PCA can also be used as a filtering approach for noisy data. The idea is this: any components with variance much larger than the effect of the noise should be relatively unaffected by the noise. So if you reconstruct the data using just the largest subset of principal components, you should be preferentially keeping the signal and throwing out the noise.
下面我们以手写体数字为例,探索PCA作为噪声过滤器的效果,首先我们画出无噪声的手写体数字:
|
|

现在我们队手写体数字添加噪声:
|
|
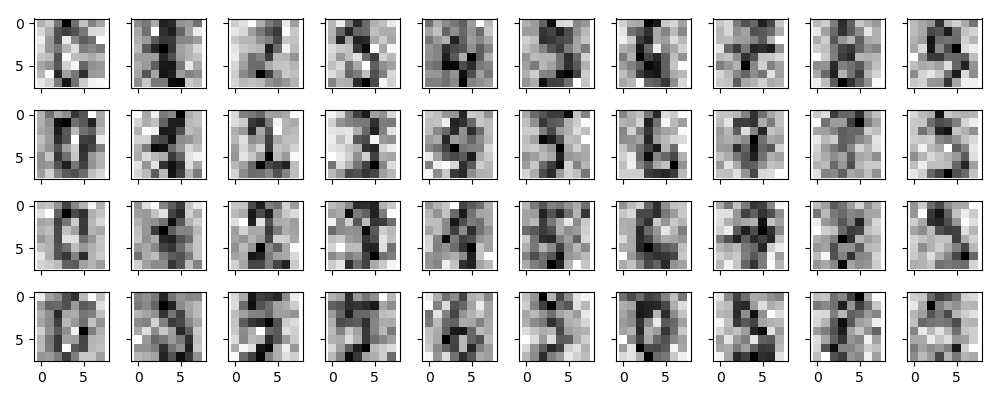
显然,添加了噪声的数据很难辨别,现在我们就去训练一个PCA进行去噪:
|
|
我们想要模型解释至少50%的变化,根据模型显示,需要12个维度。
|
|

This signal preserving/noise filtering property makes PCA a very useful feature selection routine—for example, rather than training a classifier on very high-dimensional data, you might instead train the classifier on the lower-dimensional representation, which will automatically serve to filter out random noise in the inputs.
|
|
可以看到每一张图片的维度是2941=62*47,由于数据维度比较大,这次我们使用RandomizedPCA而非标准PCA
In this case, it can be interesting to visualize the images associated with the first several principal components (these components are technically known as “eigenvectors,” so these types of images are often called “eigenfaces”). As you can see in this figure, they are as creepy as they sound:
|
|

The results are very interesting, and give us insight into how the images vary: for example, the first few eigenfaces (from the top left) seem to be associated with the angle of lighting on the face, and later principal vectors seem to be picking out certain features, such as eyes, noses, and lips. Let’s take a look at the cumulative variance of these components to see how much of the data information the projection is preserving:
|
|
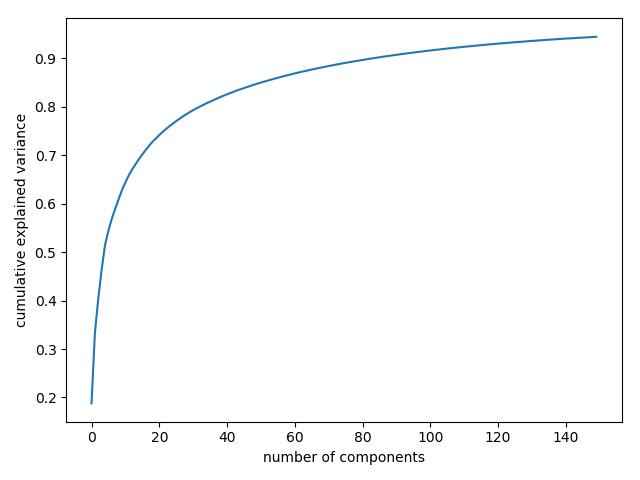
We see that these 150 components account for just over 90% of the variance. That would lead us to believe that using these 150 components, we would recover most of the essential characteristics of the data. To make this more concrete, we can compare the input images with the images reconstructed from these 150 components
|
|
