Some interesting papers that I read or am about to read.
2020
February
January
- Image Style Transfer Using Convolutional Neural Networks
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- Aggregated Residual Transformations for Deep Neural Networks
- Squeeze-and-Excitation Networks
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- Image Transformer
- Image Style Transfer Using Convolutional Neural Networks
CVPR2019
GAN
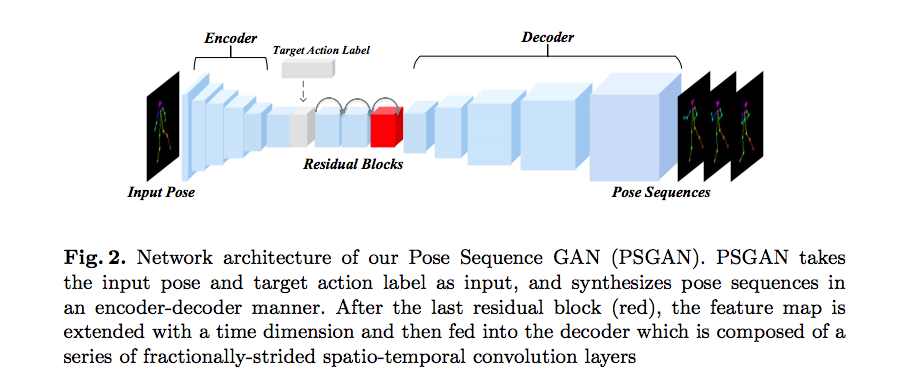
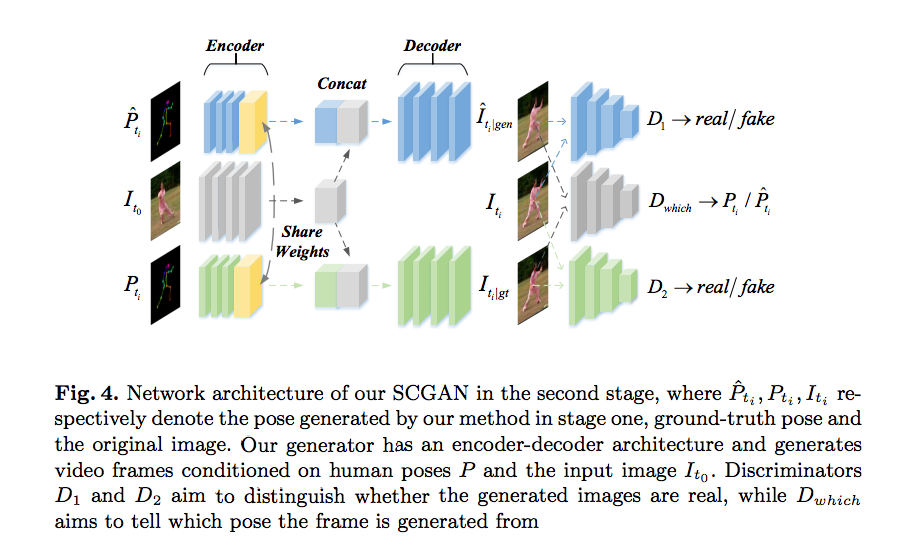
[Progressive Pose Attention Transfer for Person Image Generation](https://arxiv.org/pdf/1904.03349.pdf) code
MirrorGAN: Learning Text-to-image Generation by Redescription
Text -> Image, then Image -> Text.
Joint Discriminative and Generative Learning for Person Re-identification
Semantics Disentangling for Text-to-Image Generation
Unsupervised Person Image Generation with Semantic Parsing Transformation
2019-05-16
StoryGAN: A Sequential Conditional GAN for Story Visualization
Object-driven Text-to-Image Synthesis via Adversarial Training
Text2Scene: Generating Compositional Scenes from Textual Descriptions
DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis
Text Guided Person Image Synthesis
Inferring poses from the text and then taking one person image, text and inferred pose as input to generate person images.
Semantics Disentangling for Text-to-Image Generation
R2GAN: Cross-modal Recipe Retrieval with Generative Adversarial Network
2019-05-15
Fashion-AttGAN: Attribute-Aware Fashion Editing with Multi-Objective GAN
Improvement work based on their previous Attgan: Facial attribute editing by only changing what you want.
2019-05-14
Self-Supervised GANs via Auxiliary Rotation Loss
Traditioanal CGAN with rotation angle loss being supervising loss.
CollaGAN: Collaborative GAN for Missing Image Data Imputation
Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis
Solve the cGAN mode collapse problem by introducing a regularization term.
MirrorGAN: Learning Text-to-image Generation by Redescription
Videos
Efficient Large Scale Video Classification
Future Person Localization in First-Person Videos
NLP
2019-03-01 Convolutional Image Captioning Image captioning: describe the content observed in an image.
Reconstruction Network for Video Captioning
Learning Semantic Concepts and Order for Image and Sentence Matching
Visual Question Generation as Dual Task of Visual Question Answering
2019-02-28 Are You Talking to Me? Reasoned Visual Dialog Generation through Adversarial Learning
A Generative Adversarial Approach for Zero-Shot Learning from Noisy Texts
Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks
Actor and Action Video Segmentation from a Sentence
Objects as context for detecting their semantic parts
Six Challenges for Neural Machine Translation
AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
Images
2019-03-01 Self-Attention Generative Adversarial Networks
2019-03-02 Learning Residual Images for Face Attribute Manipulation tensorflow keras
2019-03-03 Disentangling Factors of Variation by Mixing Them
2019-03-03 Deep Semantic Face Deblurring
SGAN: An Alternative Training of Generative Adversarial Networks
DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks
2019-03-03 Face Aging With Conditional Generative Adversarial Networks
2019-03-04 Age Progression/Regression by Conditional Adversarial Autoencoder
2019-03-04 Face Aging with Identity-Preserved Conditional Generative Adversarial Networks
2019-03-05 Towards Open-Set Identity Preserving Face Synthesis
Person Transfer GAN to Bridge Domain Gap for Person Re-Identification
2019-03-08 Separating Style and Content for Generalized Style Transfer
Pose-Robust Face Recognition via Deep Residual Equivariant Mapping
Mask-aware Photorealistic Face Attribute Manipulation
2019-03-10 Perceptual Adversarial Networks for Image-to-Image Transformation
End-to-End Dense Video Captioning with Masked Transformer
2019-03-01 Predicting Yelp Star Reviews Based on Network Structure with Deep Learning
Chinese Typeface Transformation with Hierarchical Adversarial Network
Look, Imagine and Match: Improving Textual-Visual Cross-Modal Retrieval with Generative Models
Zero-Shot Visual Recognition using Semantics-Preserving Adversarial Embedding Networks
Unsupervised Domain Adaptation with Adversarial Residual Transform Networks
Learning Pose Specific Representations by Predicting Different Views
What have we learned from deep representations for action recognition?
Feature Space Transfer for Data Augmentation
Photo-realistic Facial Texture Transfer
Generating a Fusion Image: One’s Identity and Another’s Shape
FairGAN: Fairness-aware Generative Adversarial Networks
Learning Intrinsic Image Decomposition from Watching the World
Residual Dense Network for Image Super-Resolution
2019-03-20 Detecting and Recognizing Human-Object Interactions
Semantic Facial Expression Editing using Autoencoded Flow
Multi-Content GAN for Few-Shot Font Style Transfer
Load Balanced GANs for Multi-view Face Image Synthesis
Exploring Disentangled Feature Representation Beyond Face Identification
High-Quality Face Image SR Using Conditional Generative Adversarial Networks
GP-GAN: Gender Preserving GAN for Synthesizing Faces from Landmarks
3D Human Pose Estimation in the Wild by Adversarial Learning
Generative Image Inpainting with Contextual Attention
TextureGAN: Controlling Deep Image Synthesis with Texture Patches
Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks
2019-01-24
Generative Adversarial Text to Image Synthesis
2019-02-28 StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
Scribbler: Controlling Deep Image Synthesis with Sketch and Color
DEEP REINFORCEMENT LEARNING: AN OVERVIEW
Invertible Conditional GANs for image editing
A Pose-Sensitive Embedding for Person Re-Identification with Expanded Cross Neighborhood Re-Ranking
Pose Guided Person Image Generation
Human Action Generation with Generative Adversarial Networks
Deep Video Generation, Prediction and Completion of Human Action Sequences skeleton generation
Pose Guided Human Video Generation skeleton generation
SwapNet: Image Based Garment Transfer
A Variational U-Net for Conditional Appearance and Shape Generation
2019-01-04
Visualizing and Understanding Convolutional Networks
An Introduction to Image Synthesis with Generative Adversarial Nets
Generative Semantic Manipulation with Contrasting GAN
In this paper, distance loss is used to measure the difference between real/fake images.
2018-11-16
Disentangled Representation Learning GAN for Pose-Invariant Face Recognition
The authors try to solve the problem of Pose-Invariant Face Recognition.
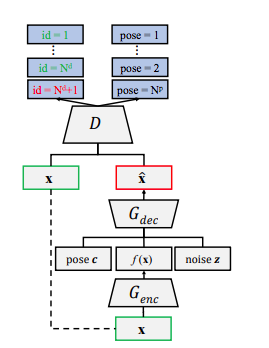
By controlling $c$ and $z$, we can diversify the generated images.
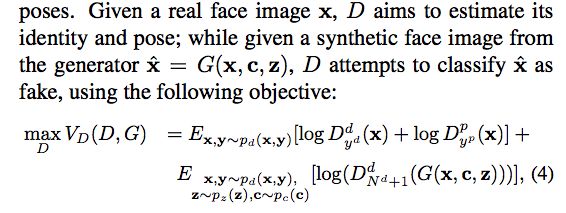
Discriminator has three tasks: classify real images as real ones, fake images as fake ones, the identities and poses.

Generator tries to maximize the accuracy of generated images being classified to the true identities and poses.
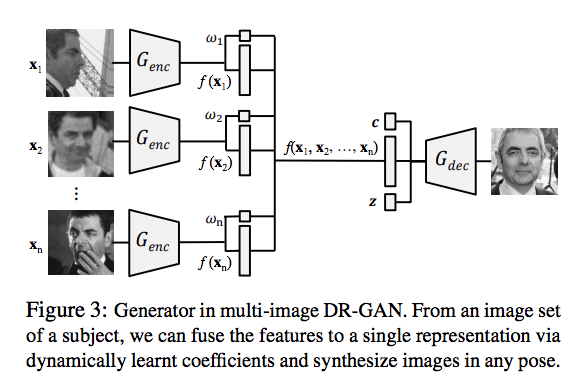
There are $n$ input images and each one has a corresponding generated image; and there is one generated image. For each generated image, there are two losses.
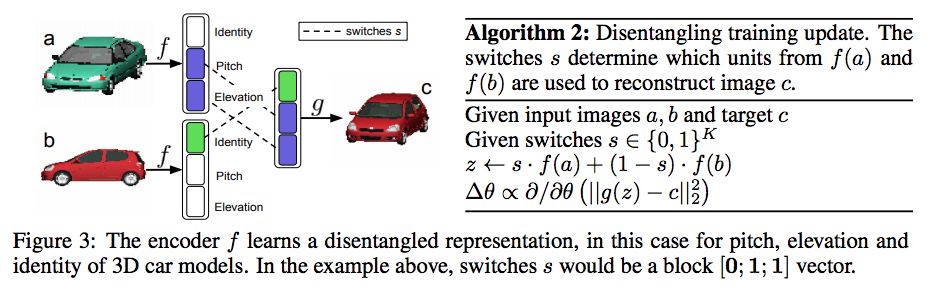
Disentangling factors of variation in deep representations using adversarial training
2018-11-15
Soft-Gated Warping-GAN for Pose-Guided Person Image Synthesis
Pose Transferrable Person Re-Identification
A Semi-supervised Deep Generative Model for Human Body Analysis
Deep Video-Based Performance Cloning
A Hybrid Model for Identity Obfuscation by Face Replacement
Shuffle-Then-Assemble: Learning Object-Agnostic Visual Relationship Features
Learning Disentangled Representations with Semi-Supervised Deep Generative Models
2018-11-10
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
Semi and Weakly Supervised Semantic Segmentation Using Generative Adversarial Network
A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
Tag Disentangled Generative Adversarial Networks for Object Image Re-rendering
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
2018-11-08
TextureGAN: Controlling Deep Image Synthesis with Texture Patches
VITAL: VIsual Tracking via Adversarial Learning
Problem setting : tracking-by-detection, i.e., drawing samples around the target object in the first stage and classifying each sample as the target object or as background in the second stage.
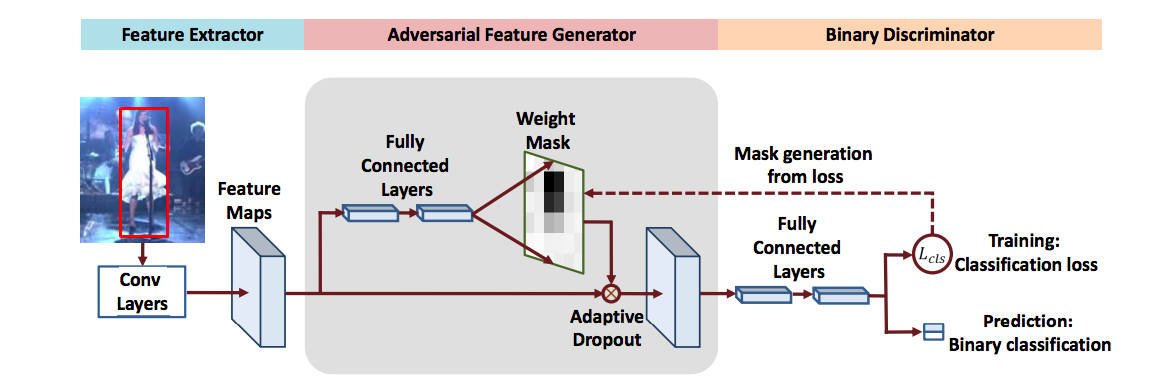
Image Denoising via CNNs: An Adversarial Approach
Image denoising is a fundamental image processing problem whose objective is to remove the noise while preserving the original image structure.
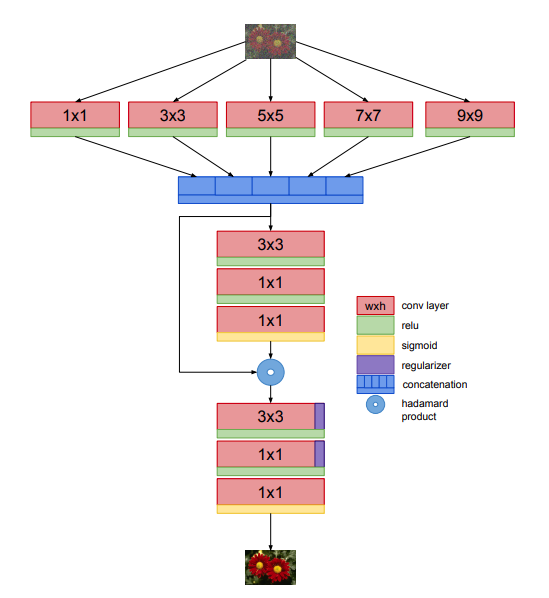
Discriminative Region Proposal Adversarial Networks for High-Quality Image-to-Image Translation
From source to target and back: symmetric bi-directional adaptive GAN
Conditional Image-to-Image Translation
Deformable Shape Completion with Graph Convolutional Autoencoders
2018-11-05
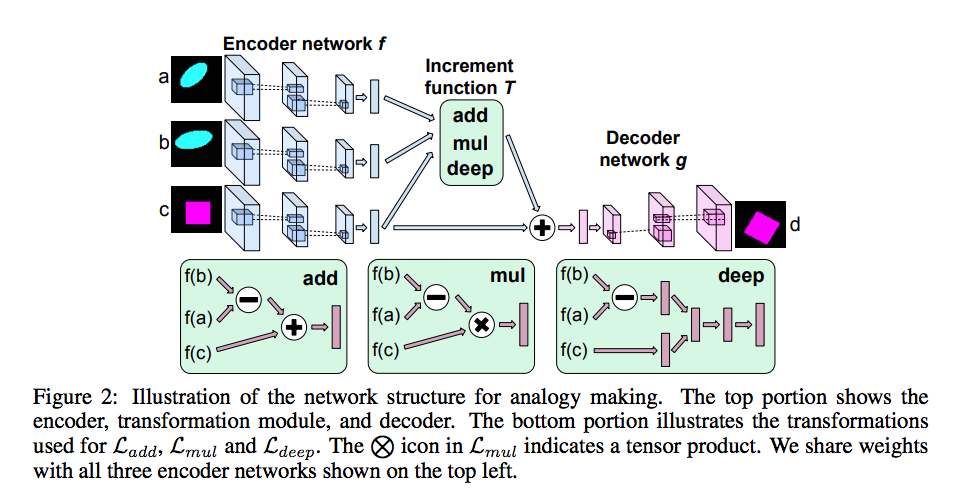
Deep Visual Analogy-Making tf code
Given a pair of images $(a,b)$ and a query image $c$, we try to generate $d$, the corresponding image of $c$, such that $a$ is to $b$ as $c$ is to $d$.
Person Transfer GAN to Bridge Domain Gap for Person Re-Identification code
A new Multi-Scene Multi-Time person ReID dataset (MSMT17) is proposed.
[transfer styles but keep identies] A method is proposed to bridge the domain gap by transferring persons in dataset A to another dataset B. The transferred persons from A are desired to keep their identities, meanwhile present similar styles, e.g., backgrounds, lightings, etc., with persons in B.
To keep identity, a identities loss is introduced where the mask region of generated images and gt images should be similar.
Separating Style and Content for Generalized Style Transfer
Connecting Pixels to Privacy and Utility: Automatic Redaction of Private Information in Images code
FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation
Disentangling 3D Pose in A Dendritic CNN for Unconstrained 2D Face Alignment
A New Representation of Skeleton Sequences for 3D Action Recognition
2018-11-04
Synthesizing Images of Humans in Unseen Poses
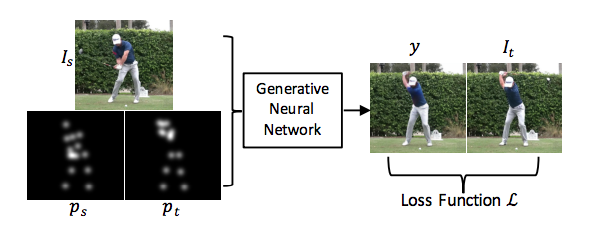
Our model is trained on (example, label) tuples of the form $((I_s, p_s, p_t), I_t)$, where $I_s$, $p_s$ and $p_t$ are the source image, source 2D pose and target 2D pose, and $I_t$ is the target image.
our model first segments the scene into foreground and background layers. It further segments the person’s body into different part layers such as the arms and legs, allowing each part to then be moved independently of the others.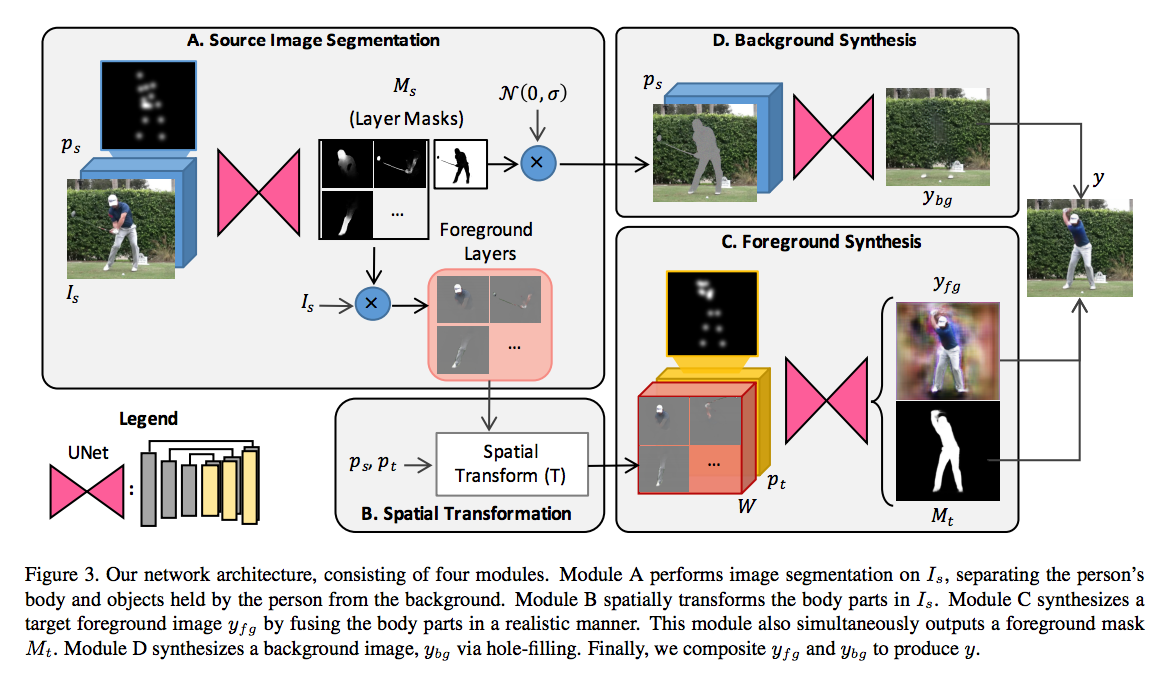
Generating a Fusion Image: One’s Identity and Another’s Shape
Given two rgb images $x $ and $y$, we try to generate a new image which is the combination of the identity $x$ and the shape or pose of $y$.
A Generative Model of People in Clothing
The authors try to generate different people with different clothes but with the same specified shapes.
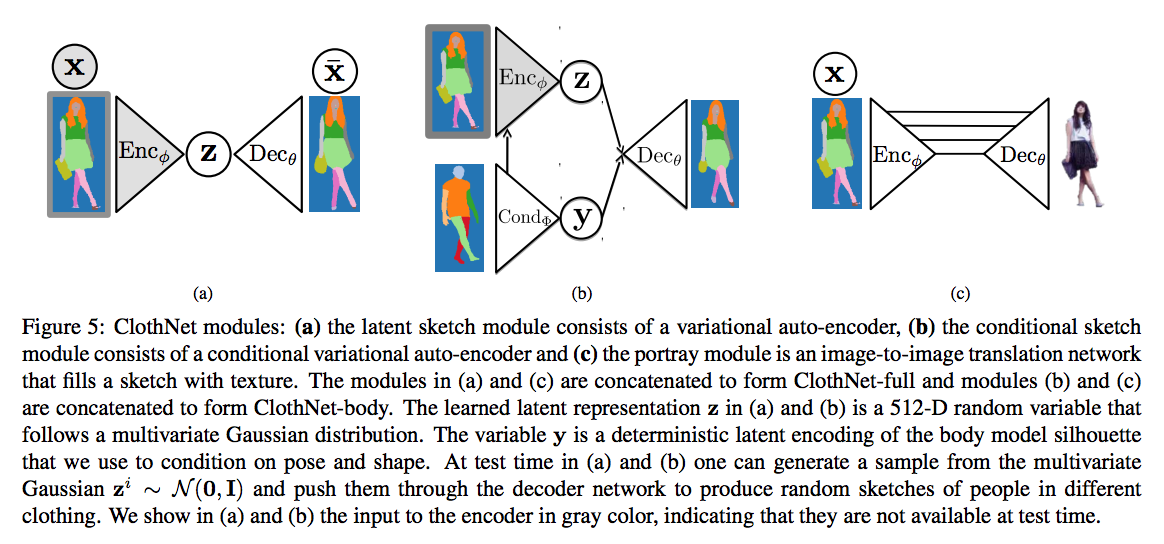
2018-11-2
Multimodal Deep Learning for Robust RGB-D Object Recognition
Depth-aware CNN for RGB-D Segmentation
Learning Rich Features from RGB-D Images for Object Detection and Segmentation
Deep Bilinear Learning for RGB-D Action Recognition
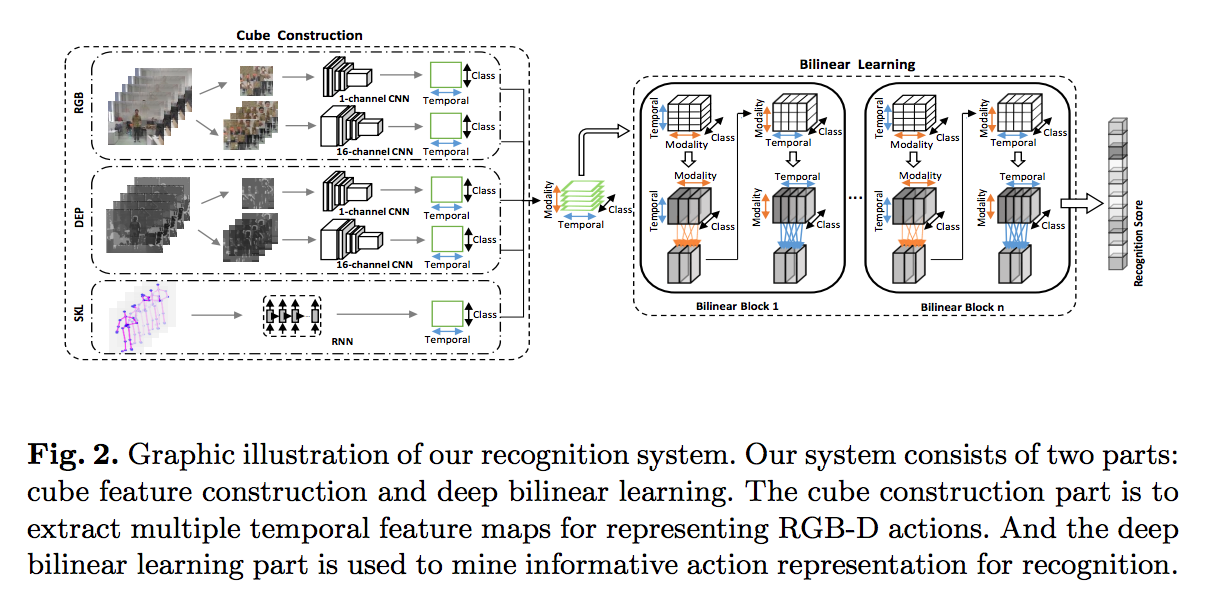
In this paper, we present a novel tensor-structured cube feature【The multi-modal sequences with temporal information can be regarded as a tensor, structured with two different dimensions (temporal and modality)】, and propose to learn time-varying information from multi-modal action history sequences for RGB-D action recognition.
In this paper, we address this challenge by proposing a novel deep bilinear framework, where a bilinear block consisting of two linear pooling layers (modality pooling layer and temporal pooling layer) is defined to pool the input tensor along the modality and temporal directions, separately. In this way, the structures along the temporal and modal dimensions are both preserved. By stacking the proposed bilinear blocks and other network layers (e.g., Relu and softmax), we develop our deep bilinear model to jointly learn the action history and modality information in videos. Results have shown that learning modality-temporal mutual information is beneficial for the recognition of RGB-D actions.
2018-10-31
A Pose-Sensitive Embedding for Person Re-Identification with Expanded Cross Neighborhood Re-Ranking
coarse pose : front, back, side of a person’s orientation to the camera.
fine pose : joint skeleton
Everybody Dance Now
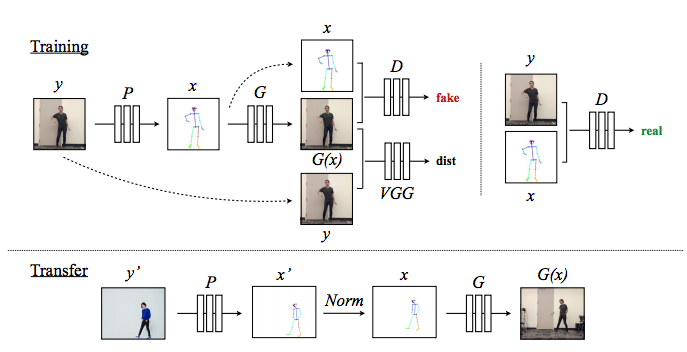
The task is to generate a action video conditioned on the figure and source video.
The problem is you have to train a generate G model for each new person.
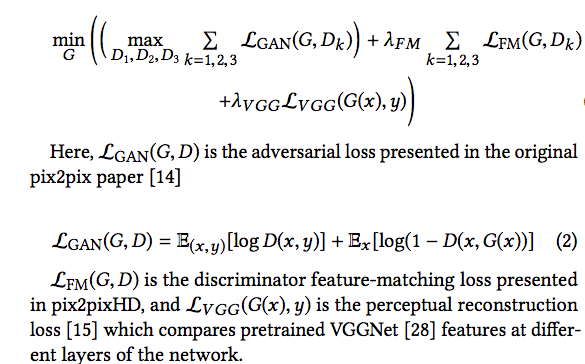
$L_{VGG}$ loss: instead of using per-pixel loss functions depending only on low-level pixel information, we train our networks using perceptual loss functions that depend on high-level features from a pretrained loss network. During training, perceptual losses measure
image similarities more robustly than per-pixel losses
CR-GAN: Learning Complete Representations for Multi-view Generation
- learn complete representation to handle unseen data problem.
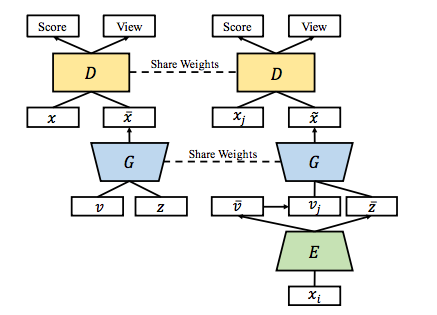
The authors aim to geneate multi-view images of a figure given one image of that person.
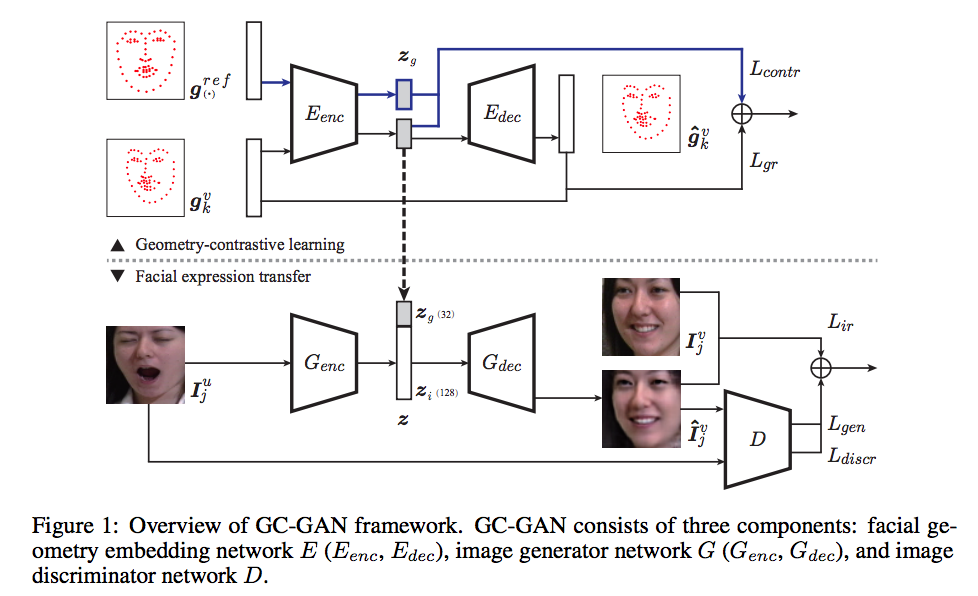
Geometry-Contrastive GAN for Facial Expression Transfer
- handle the misalignment across different subjects or facial expressions.
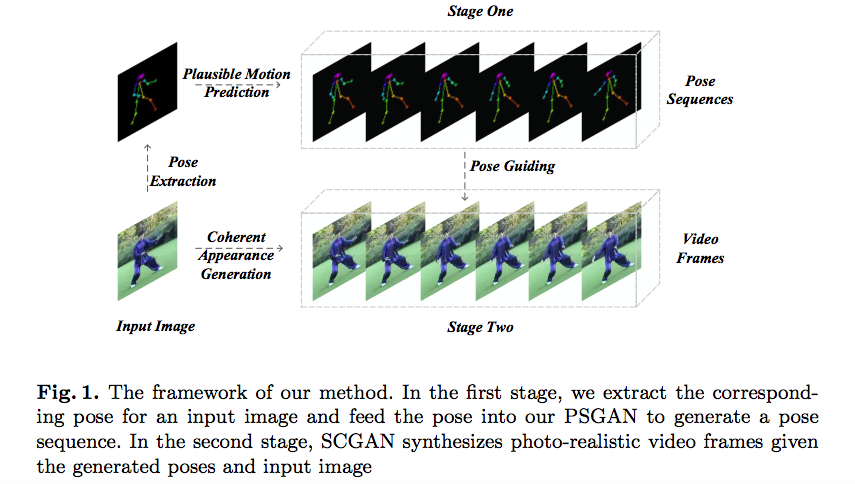
Pose Guided Human Video Generation
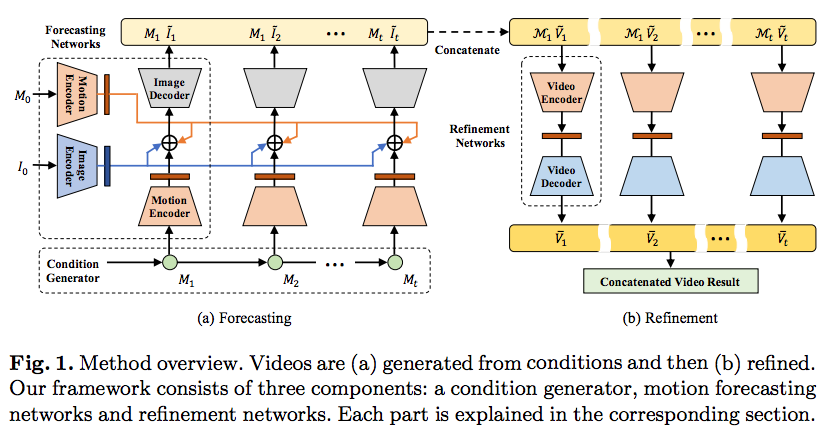
DDDDDDDIFFICULTLearning to Forecast and Refine Residual Motion for Image-to-Video Generation
we study a form of classic problems in video generation that can be framed as
image-to-video translation tasks, where a system receives one or more images
as the input and translates it into a video containing realistic motions of a
single object.
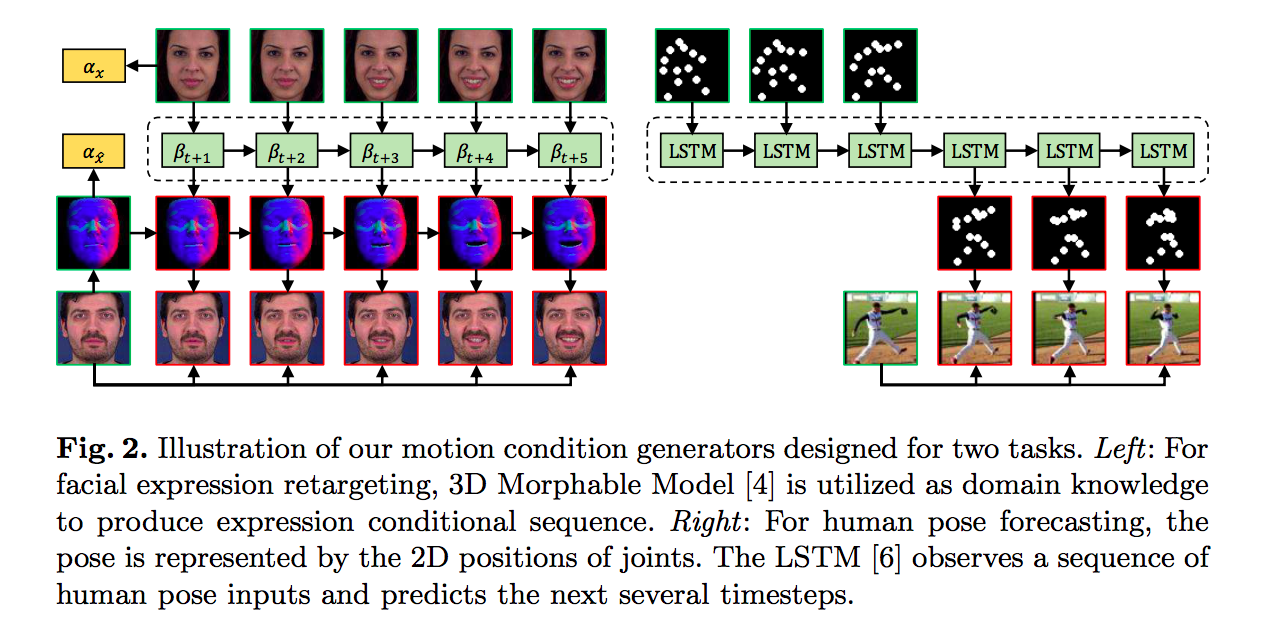
2018-10-29
Pose-Normalized Image Generation for Person Re-identification
Critically, once trained, the model can be applied to a new dataset without any model fine-tuning as long as the test image’s pose is also normalized.
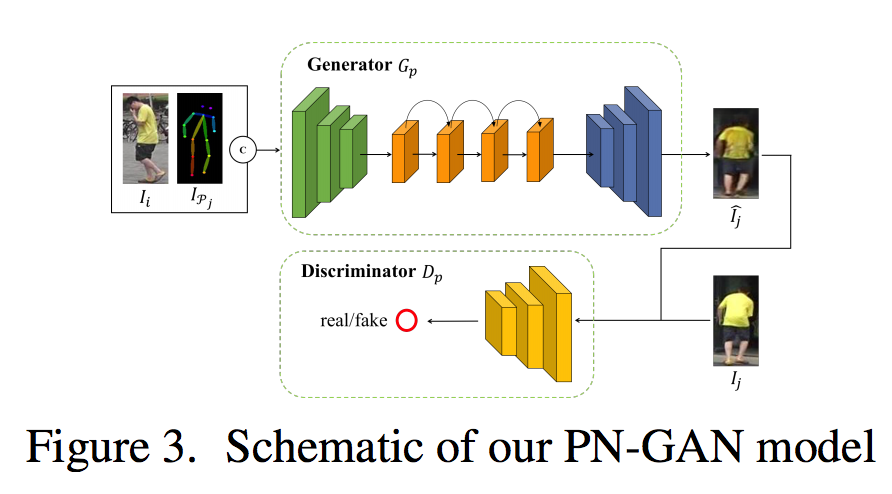
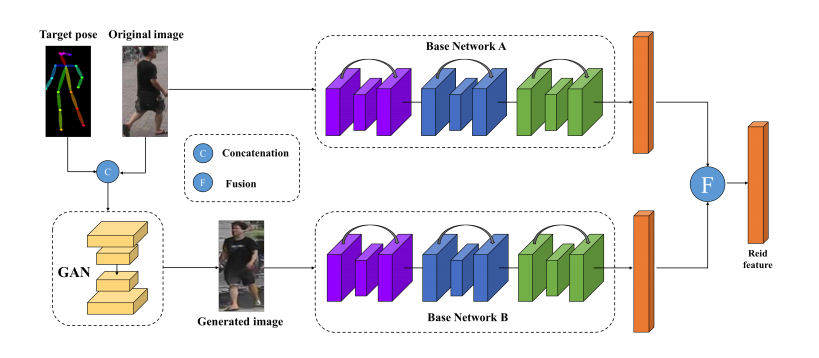
we train two re-id models. One model is trained using the original images in a training set to extract identity-invariant features in the presence of pose variation. The other is trained using the synthesized images with normalized poses using our PN-GAN to compute re-id features free of pose variation. They are then fused as the final feature representat.
VITON: An Image-based Virtual Try-on Network
We present an image-based virtual try-on approach, relying merely on plain RGB images without leveraging any 3D information. we propose a virtual try-on network (VITON), a coarse-to-fine framework that seamlessly transfers a target clothing item in a product image to the corresponding region of a clothed person in a 2D image.
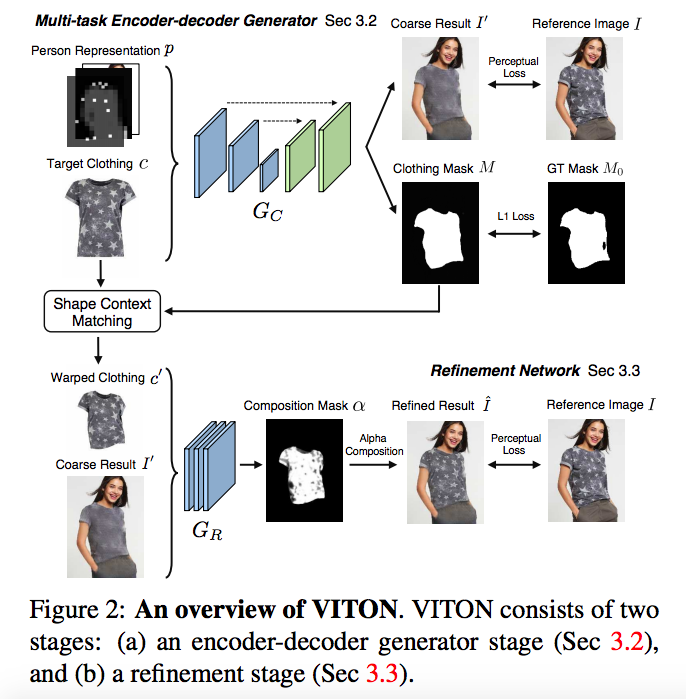
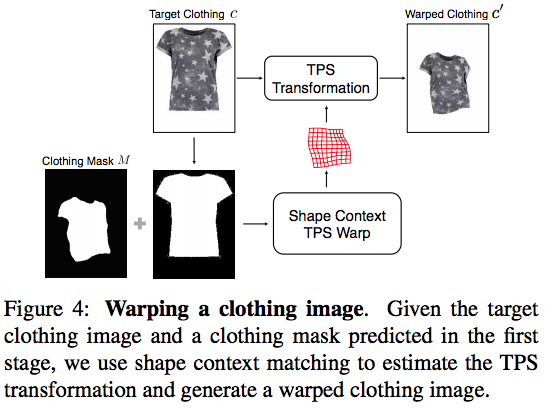
The mask is then used as a guidance to warp the target clothing item to account for deformations.
Disentangled Person Image Generation
Generating novel, yet realistic, images of persons is a challenging task due to the complex interplay between the different image factors, such as the foreground, background and pose information. In this work, we aim at generating such images based on a novel, two-stage reconstruction pipeline that learns a disentangled representation of the aforementioned image factors and generates novel person images at the same time.
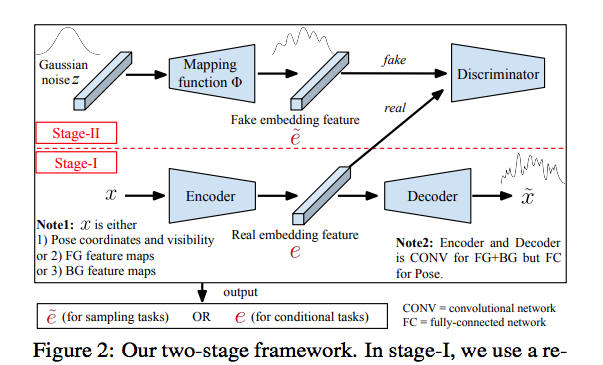

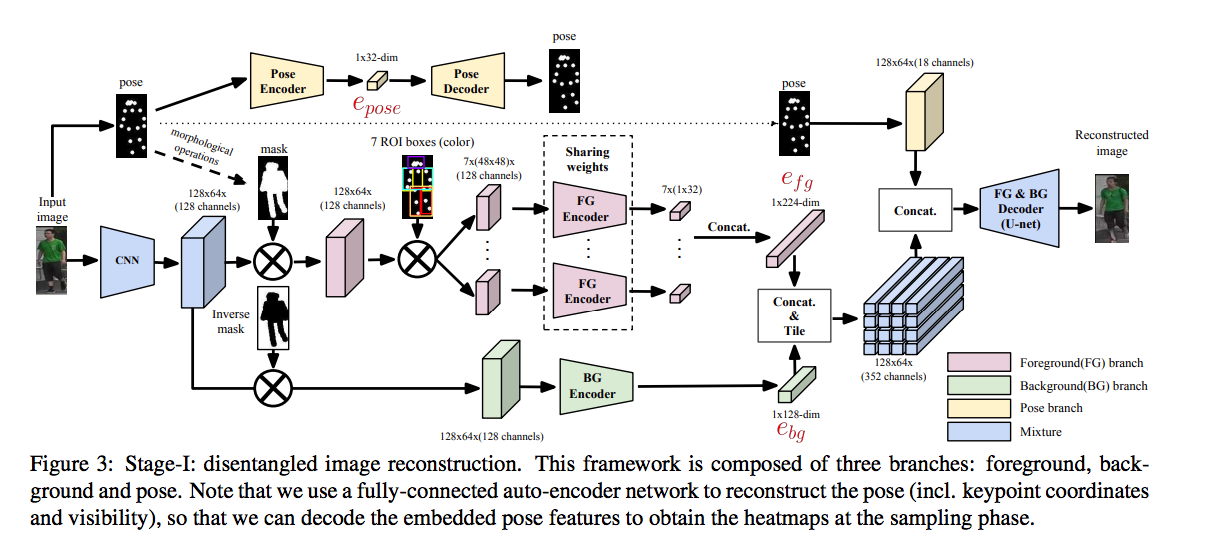
In stage one, a real image is used to train 3 independent encoders, i.e., Pose Encoder, Foreground Encoder, and Background Encoder.
In stage two, we can smaple features from 3 encoders respectively to get pose features, foreground features and background features. And combining these three features to generate imagse.
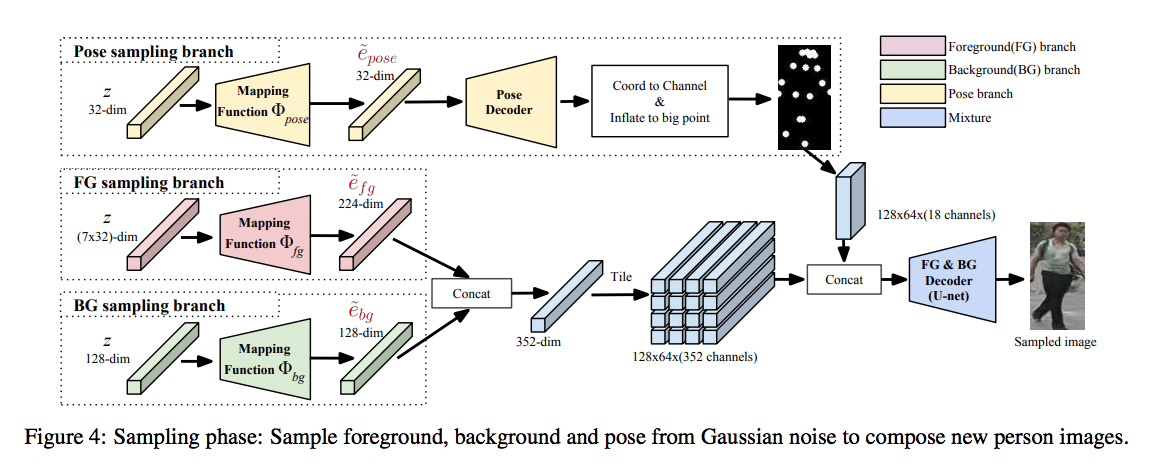
In particular, we aim at sampling from a standard distribution, e.g. a Gaussian
distribution, to first generate new embedding features and from them generate new images
Natural and Effective Obfuscation by Head Inpainting
- detecting 68 facial keypoints using the python dlib toolbox paper
-
We focus on the scenario where the user wants to obfuscate some identities in a social media photo by inpainting new heads for them. We use facial landmarks to provide strong guidance for the head inpainter. We factor the head inpainting task into two stages: (1) landmark detection or generation and (2) head inpainting conditioned on body context and landmarks.
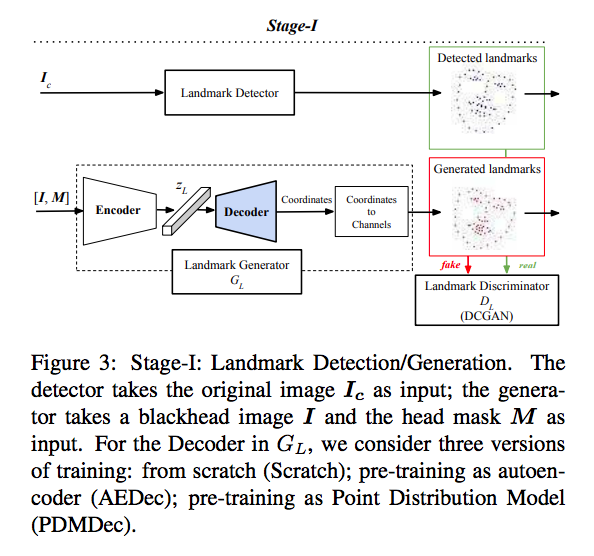
It takes either the original or blackhead image as input, in order to give flexibility to deal with cases where the original images are not available.
Given original or headobfuscated input, stage-I detects or generates landmarks,
respectively. Stage-II takes the blackhead image and landmarks as input, and outputs the generated image.
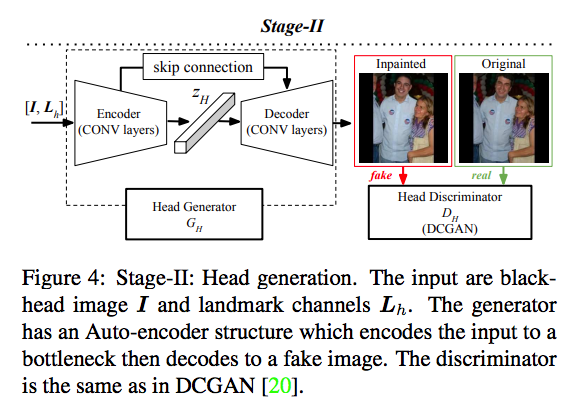
Deformable GANs for Pose-based Human Image Generation
Specifically, given an image of a person and a target pose, we synthesize a new image of that person in the novel pose. In order to deal with pixel-to-pixel misalignments caused by the pose differences, we introduce deformable skip connections in the generator of our Generative Adversarial Network.
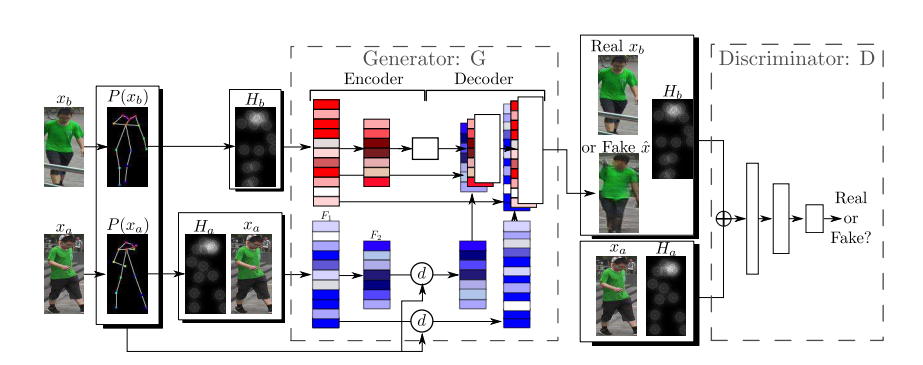
2018-10-27
Cross-Modality Person Re-Identification with Generative Adversarial Training
studied the Re-ID between infrared and RGB images, which is essentially a cross-modality problem and widely encountered in real-world scenarios.
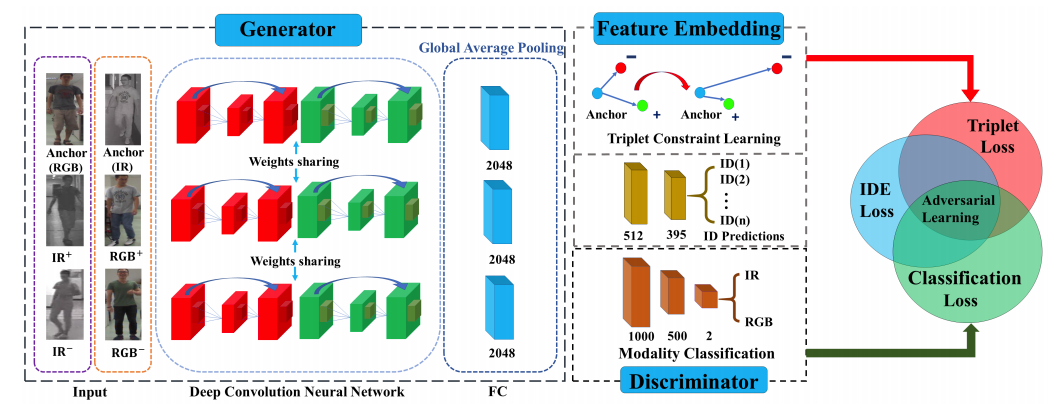
Predicting Human Interaction via Relative Attention Model
Essentially, a good algorithm should effectively model the mutual influence between the two interacting subjects. Also, only a small region in the scene is discriminative for identifying the on-going interaction.
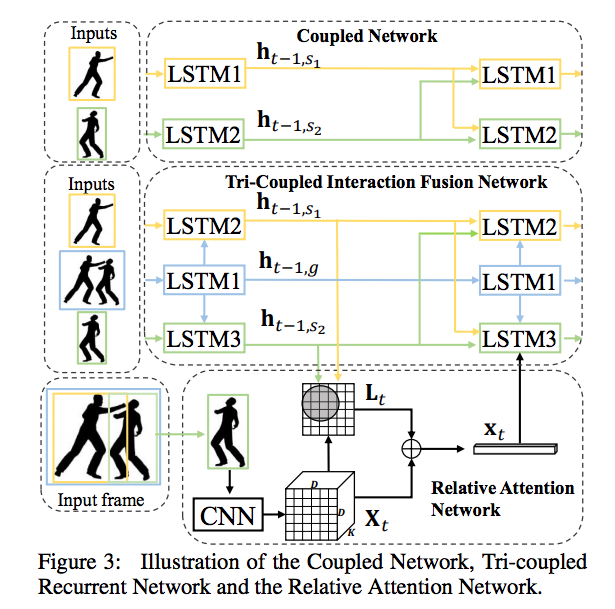
An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data
We build our model on top of the Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM), which learns to selectively focus on discriminative joints of skeleton within each frame of the inputs and pays different levels of attention to the outputs of different frames.
For spatial joints of skeleton, we propose a spatial attention module which conducts automatic mining of discriminative joints. A certain type of action is usually only associated with and characterized by the combinations of a subset of kinematic joints.
For a sequence, the amount of valuable information provided by different frames is in general not equal. Only some of the frames (key frames) contain the most discriminative information while the other frames provide context information.

Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation
focus on the problem of skeleton-based human action recognition and detection.
By investigating the convolution operation, we may decompose it into two steps, i.e. local feature aggregation across the spatial domain (width and height) and global feature aggregation across channels.
The input is skeleton sequences and skeleton temporal differences.
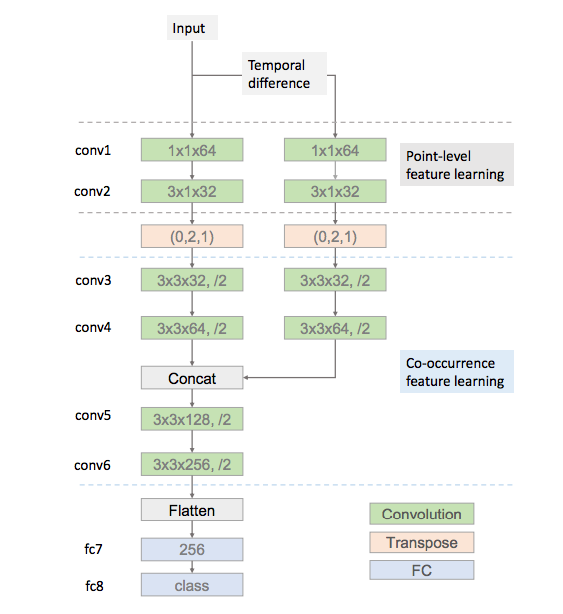
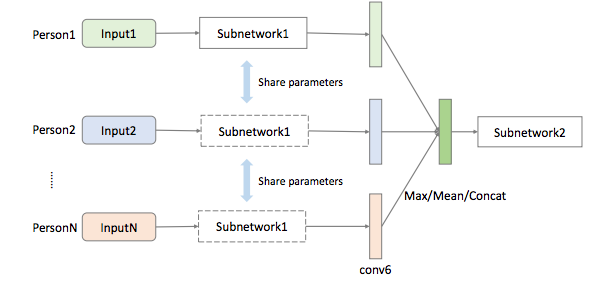
For multiple persons, inputs of multiple persons go through the same subnetwork and their conv6 feature maps are merged with either concatenation along channels or element-wise maximum / mean operation.
Action detection
Pose Guided Person Image Generation

https://arxiv.org/pdf/1601.01006.pdf
A2g-GAN
2018-10-26
IJCAI 2018
Exploiting Images for Video Recognition with Hierarchical Generative Adversarial Networks
The two-level HiGAN is designed to have a low-level conditional GAN and a high-level conditional GAN. The low-level conditional GAN is built to connect videos and their corresponding video frames by learning a mapping function from frame features to video features in the target domain. The high-level conditional GAN, on the other hand, is modeled to bridge the gap between source images and target videos by formulating a mapping function from video features to image-frame features.
Memory Attention Networks for Skeleton-based Action Recognition
2018-10-25
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Pose Guided Person Image Generation
Disentangled Person Image Generation
Deformable GANs for Pose-based Human Image Generation
2018-10-23
Generating Realistic Videos from Keyframes with Concatenated GANs
Given two video frames X0 and Xn+1, we aim to generate a series of intermediate frames Y1, Y2, · · · , Yn, such that the resulting video consisting of frames X0, Y1-Yn, Xn+1 appears realistic to a human watcher.
Human Action Generation with Generative Adversarial Networks

Deep Video Generation, Prediction and Completion of Human Action Sequences
The model itself
is originally desi gne d for video generation, i.e., generating human action videos
from random noise. We split the generation process into two stages: first, we
generate human skeleton sequences from random noise, and then we t r an sf orm
from the skeleton images to the real pixel-level images.
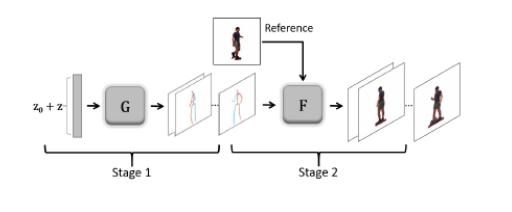
The model is independent of training subjests, where we train the model using some subjects but test it using totally different subjects.