Double Q-Learning in Reinforcement Learning.
Problem in Q-Learning
Consider an MDP having four states two of which are terminal states. State A is always considered at start state, and has two actions, either Right or Left. The Right action gives zero reward and lands in terminal state C. The Left action moves the agent to state B with zero reward.
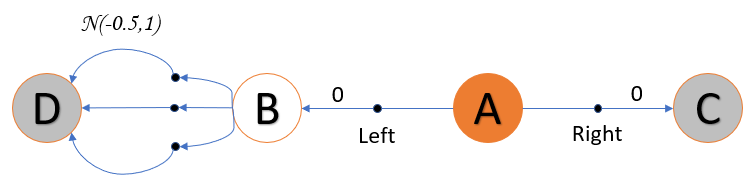
State B has a number of actions, they move the agent to the terminal state D. However (this is important) the reward R of each action from B to D has a random value that follows a normal distribution with mean -0.5 and a variance 1.0.
The expected value of R is known to be negative (-0.5). This means that over a large number of experiments the average value of R is less than zero.
Based on this assumption, it is clear that moving left from A is always a bad idea. However because some of the values of R are positive, Q-Learning will be tricked to consider that moving left from A maximises the reward. In reality this is a bad decision, because even if it works for some episodes, on the long run it is guaranteed to be a negative reward.