Q-Learning needs to maintain a Q-table that an agent uses to find the best action to take given a state. However, producing and updating a Q-table can become ineffective in big state space environments. While in this post, we are going to create a Deep Q Neural Network to improve Q Learning. Instead of using a Q-table, we’ll implement a Neural Network that takes a state and approximates Q-values for each action based on that state. ref
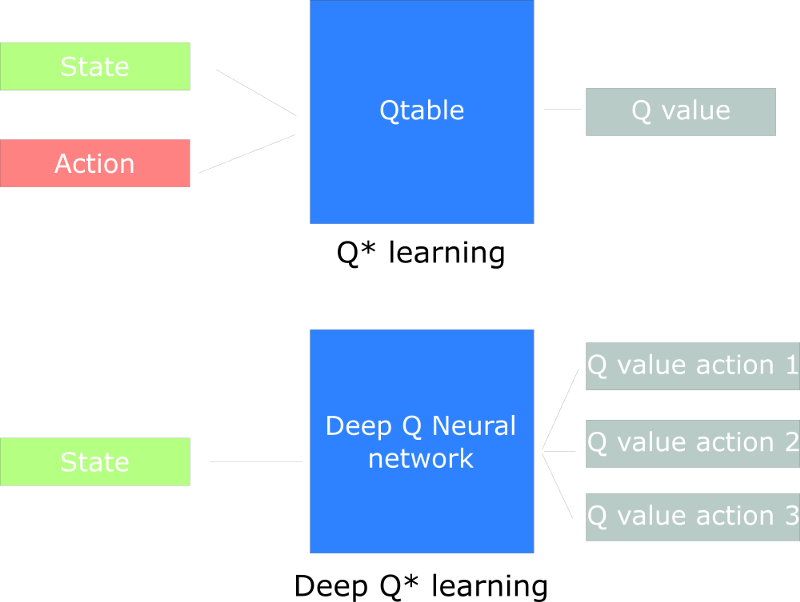
Overall Structure

Our Deep Q Neural Network takes a stack of four frames as an input. These pass through its network, and output a vector of Q-values for each action possible in the given state. We need to take the biggest Q-value of this vector to find our best action.
In the beginning, the agent does really badly. But over time, it begins to associate frames (states) with best actions to do.
Preprocessing

Preprocessing is an important step. We want to reduce the complexity of our states to reduce the computation time needed for training. First, we can grayscale each of our states. Color does not add important information (in our case, we just need to find the enemy and kill him, and we don’t need color to find him). This is an important saving, since we reduce our three colors channels (RGB) to 1 (grayscale). Then, we crop the frame. In our example, seeing the roof is not really useful. Then we reduce the size of the frame, and we we stack four sub-frames together.
The problem of temporal limitation
Arthur Juliani gives an awesome explanation about this topic in his article. He has a clever idea: using LSTM neural networks for handling the problem.
The first question that you can ask is why we stack frames together? We stack frames together because it helps us to handle the problem of temporal limitation. Let’s take an example, in the game of Pong. When you see this frame:
Can you tell me where the ball is going? No, because one frame is not enough to have a sense of motion! But what if I add three more frames? Here you can see that the ball is going to the right.

That’s the same thing for our Doom agent. If we give him only one frame at a time, it has no idea of motion. And how can it make a correct decision, if it can’t determine where and how fast objects are moving?
Convolution network
The frames are processed by three convolution layers. These layers allow you to exploit spatial relationships in images. But also, because frames are stacked together, you can exploit some spatial properties across those frames.
We use one fully connected layer with ELU activation function and one output layer (a fully connected layer with a linear activation function) that produces the Q-value estimation for each action.
Deep Q-Learning algorithm
Remember that we update our Q value for a given state and action using the Bellman equation: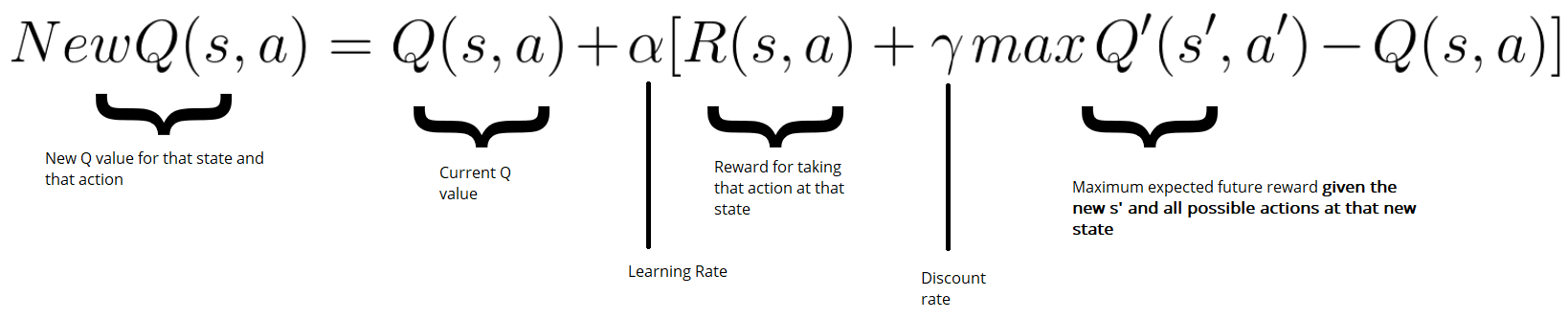
In our case, we want to update our neural nets weights to reduce the error.
The error (or TD error) is calculated by taking the difference between our Q_target (maximum possible value from the next state) and Q_value (our current prediction of the Q-value)

|
|
There are two processes that are happening in this algorithm:
- We sample the environment where we perform actions and store the observed experiences tuples in a replay memory.
- Select the small batch of tuple random and learn from it using a gradient descent update step.
Implementation
In this implementation, we are going to train a Deep Q Learning agent on the CartPole-v0 task. In this task, the agent can take two actions - moving the cart left or right, so that the pole attached to it stays upright.