Tutorials of PyTorch and some useful tips.
Pytorch 101
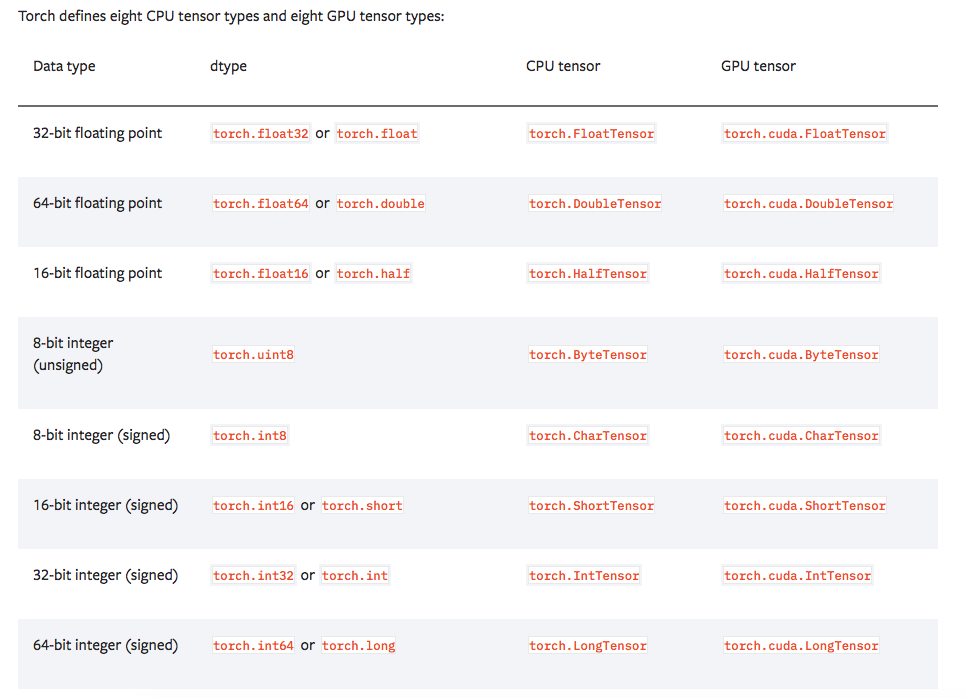
GPU vs CPU
|
|
Weight Initialization
|
|
The basics
In this section, we’ll go through the basic ideas of PyTorch starting at tensors and computational graphs and finishing at the Variable class and the PyTorch autograd functionality.
Computational graphs
The first thing to understand about any deep learning library is the idea of a computational graph. A computational graph is a set of calculations, which are called nodes, and these nodes are connected in a directional ordering of computation. In other words, some nodes are dependent on other nodes for their input, and these nodes in turn output the results of their calculations to other nodes. A simple example of a computational graph for the calculation $a=(b+c)*(c+2)$ can be seen below – we can break this calculation up into the following steps/nodes:
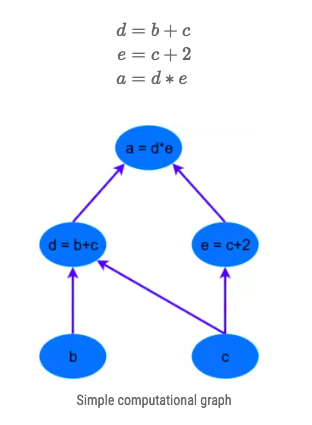
The benefits of using a computational graph is that each node is like its own independently functioning piece of code (once it receives all its required inputs). This allows various performance optimizations to be performed in running the calculations such as threading and multiple processing / parallelism. All the major deep learning frameworks (TensorFlow, Theano, PyTorch etc.) involve constructing such computational graphs, through which neural network operations can be built and through which gradients can be back-propagated.
Tensors
Tensors are matrix-like data structures which are essential components in deep learning libraries and efficient computation. Graphical Processing Units (GPUs) are especially effective at calculating operations between tensors, and this has spurred the surge in deep learning capability in recent times. In PyTorch, tensors can be declared simply in a number of ways:
|
|
This code creates a tensor of size (2, 3) – i.e. 2 rows and 3 columns, filled with zero float values.
We can also create tensors filled random float values:
|
|
Multiplying tensors, adding them and so forth is straight-forward:
|
|
Another great thing is the numpy slice functionality that is available – for instance y[:, 1]
|
|
Numpy Bridge
Converting a Torch Tensor to a NumPy array and vice versa is a breeze. The Torch Tensor and NumPy array will share their underlying memory locations (if the Torch Tensor is on CPU), and changing one will change the other.
Converting a Torch Tensor to a NumPy Array
|
|
Converting NumPy Array to Torch Tensor
|
|
torch.Tensor is the central class of the package. If you set its attribute .requires_grad as True, it starts to track all operations on it. When you finish your computation you can call .backward() and have all the gradients computed automatically. The gradient for this tensor will be accumulated into .grad attribute.
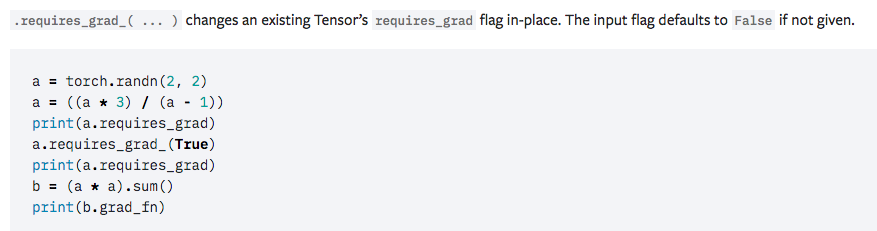
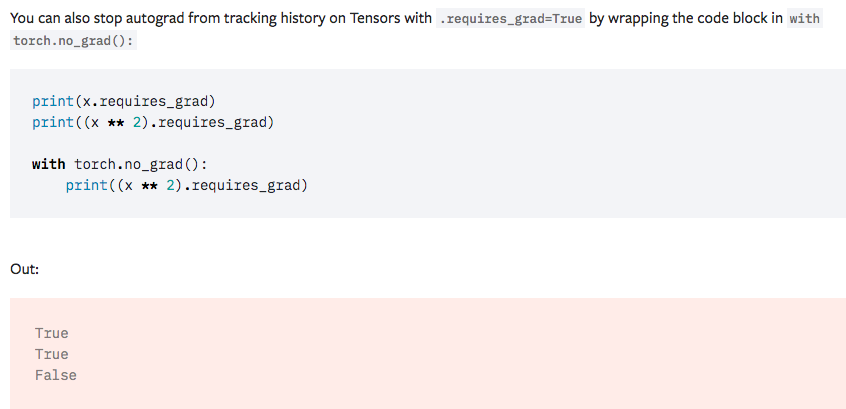
Autograd in Pytorch
n any deep learning library, there needs to be a mechanism where error gradients are calculated and back-propagated through the computational graph. This mechanism, called autograd in PyTorch. Pytorch allows automatic gradient computation on the tensor when the .backward() function is called.
|
|
do a tensor operation:
|
|
y was created as a result of an operation, so it has a grad_fn.
|
|
do more operations on y:
|
|
Gradients
Let’s backprop now. Because out contains a single scalar, out.backward() is equivalent to out.backward(torch.tensor(1.)).
|
|
Print gradients d(out)/dx
|
|
Torch
Tensor
The torch package contains data structures for multi-dimensional tensors and mathematical operations over these are defined.
Creation Ops
tensor
|
|
Constructs a tensor with data.
topk
|
|
Returns the k largest elements of the given input tensor along a given dimension.
If dim is not given, the last dimension of the input is chosen.
If largest is False then the k smallest elements are returned.
A namedtuple of (values, indices) is returned, where the indices are the indices of the elements in the original input tensor.
view
|
|
Returns a new tensor with the same data as the self tensor but of a different shape.
size
|
|
Returns the size of the self tensor. The returned value is a subclass of tuple.
div
|
|
Divides each element of the input input with the scalar value and returns a new resulting tensor.
mm
|
|
matrxi multiply. see torch.mm().
torch.from_numpy
|
|
Creates a Tensor from a numpy.ndarray.
The returned tensor and ndarray share the same memory. Modifications to the tensor will be reflected in the ndarray and vice versa. The returned tensor is not resizable.
Autograd
torch.autograd provides classes and functions implementing automatic differentiation of arbitrary scalar valued functions.
Variable (deprecated)
The Variable API has been deprecated: Variables are no longer necessary to use autograd with tensors. Autograd automatically supports Tensors with requires_grad set to True. Below please find a quick guide on what has changed:
Variable(tensor)andVariable(tensor, requires_grad)still work as expected, but they return Tensors instead of Variables.var.datais the same thing astensor.data.- Methods such as
var.backward(), var.detach(), var.register_hook()now work on tensors with the same method names.
max
- 1torch.max(input) -> Tensor
Returns the maximum value of all elements in the
inputtensor.12345a = torch.randn(1, 3)atensor([[ 0.6763, 0.7445, -2.2369]])torch.max(a)tensor(0.7445) - 1torch.max(input, dim, keepdim=False, out=None) -> (Tensor, LongTensor)
Returns a namedtuple
(values, indices)wherevaluesis the maximum value of each row of theinputtensor in the given dimensiondim. Andindicesis the index location of each maximum value found (argmax).If
keepdimisTrue, the output tensors are of the same size asinputexcept in the dimensiondimwhere they are of size 1. Otherwise,dimis squeezed (seetorch.squeeze()), resulting in the output tensors having 1 fewer dimension thaninput.- input (Tensor) – the input tensor
- dim (int) – the dimension to reduce
- keepdim (bool, optional) – whether the output tensors have
dimretained or not. Default:False. - out (tuple, optional) – the result tuple of two output tensors (max, max_indices)
12345678a = torch.randn(4, 4)atensor([[-1.2360, -0.2942, -0.1222, 0.8475],[ 1.1949, -1.1127, -2.2379, -0.6702],[ 1.5717, -0.9207, 0.1297, -1.8768],[-0.6172, 1.0036, -0.6060, -0.2432]])torch.max(a, 1)torch.return_types.max(values=tensor([0.8475, 1.1949, 1.5717, 1.0036]), indices=tensor([3, 0, 0, 1])) - 1torch.max(input, other, out=None) → Tensor
Each element of the tensor
inputis compared with the corresponding element of the tensorotherand an element-wise maximum is taken.12345678a = torch.randn(4)atensor([ 0.2942, -0.7416, 0.2653, -0.1584])b = torch.randn(4)btensor([ 0.8722, -1.7421, -0.4141, -0.5055])torch.max(a, b)tensor([ 0.8722, -0.7416, 0.2653, -0.1584])
cat
|
|
multinomial
|
|
nn
functional
Linear layers
Linear
|
|
Applies a linear transformation to the incoming data: $y=x A^{T}+b$.
- in_features – size of each input sample
- out_features – size of each output sample
- bias – If set to
False, the layer will not learn an additive bias. Default:True
Variables - Linear.weight and Linear.bias
Convolution layers
Conv2d
|
|
dilationcontrols the spacing between the kernel points; also known as the à trous algorithm. It is harder to describe, but this link has a nice visualization of whatdilationdoes.
Variables - Conv2d.weight and Conv2d.bias
Non-linear activations
Relu
|
|
Softmax
|
|
LogSoftmax
|
|
Applies the Log(Softmax(x)) function to an n-dimensional input Tensor.
CrossEntropyLoss
|
|
This criterion combines nn.LogSoftmax() and nn.NLLLoss() in one single class.
Therefore, in network architecture, we should not define a softmax layer.
NLLLoss()
go with LogSoftmax.
Layers
Embedding
|
|
Shape
- Input: (*)(∗), LongTensor of arbitrary shape containing the indices to extract
- Output: (, H)(∗,H), where is the input shape and $H=\text{embedding_dim}$
Parameters
- num_embeddings(int) -
- embedding_dim(int) - size of each embedding vector
- padding_idx(int,optional) - If given, pads the output with the embedding vector at
padding_idx(initialized to zeros) whenever it encounters the index. understanding
GRU
|
|
Parameters
- input_size - The number of expected features in the input x
- hidden_szie - The number of features in the hidden state h
- num_layers - Number of recurrent layers. E.g., setting
num_layers=2would mean stacking two GRUs together to form a stacked GRU, with the second GRU taking in outputs of the first GRU and computing the final results. Default: 1
optim
Adam
|
|
[Utils]
DATA
torch.utils.data.DataLoader
|
|
- dataset (Dataset) – dataset from which to load the data.
- batch_size (int, optional) – how many samples per batch to load (default:
1). - shuffle (bool, optional) – set to
Trueto have the data reshuffled at every epoch (default:False). - sampler (Sampler, optional) – defines the strategy to draw samples from the dataset. If specified,
shufflemust be False. - batch_sampler (Sampler, optional) – like sampler, but returns a batch of indices at a time. Mutually exclusive with
batch_size,shuffle,sampler, anddrop_last. - num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default:
0)
torch.utils.data.Sampler
|
|
Base class for all Samplers.
Every Sampler subclass has to provide an iter method, providing a way to iterate over indices of dataset elements, and a len method that returns the length of the returned iterators.
torch.utils.data.SubsetRandomSampler
|
|
Samples elements randomly from a given list of indices, without replacement.
- indices (sequence) – a sequence of indices
Torchvision
Models
|
|
All pre-trained models expect input images normalized in the same way, i.e. mini-batches of 3-channel RGB images of shape (3 x H x W), where H and W are expected to be at least 224. The images have to be loaded in to a range of [0, 1] and then normalized using mean = [0.485, 0.456, 0.406] and std = [0.229, 0.224, 0.225]. You can use the following transform to normalize:
|
|
Stop-undating
|
|
Datasets
All datasets are subclasses of torch.utils.data.Dataset i.e, they have __getitem__ and __len__ methods implemented. Hence, they can all be passed to a torch.utils.data.DataLoader which can load multiple samples parallelly using torch.multiprocessing workers.
|
|
The following datasets are available: MNIST, COCO (Captions and Detection), LSUN, ImageNet, CIFAR etc.
All the datasets have almost similar API. They all have two common arguments: transform and target_transform to transform the input and target respectively.
MNIST
|
|
- root (string) – Root directory of dataset where
MNIST/processed/training.ptandMNIST/processed/test.ptexist. - train (bool, optional) – If True, creates dataset from
training.pt, otherwise fromtest.pt. - download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
- transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g,
transforms.RandomCrop - target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
Transforms
Compose
|
|
Composes several transforms together.
- transforms (list of
Transformobjects) – list of transforms to compose.
|
|
Resize
|
|
Resize the input PIL Image to the given size.
- size (sequence or int) – Desired output size. If size is a sequence like (h, w), output size will be matched to this. If size is an int, smaller edge of the image will be matched to this number. i.e, if height > width, then image will be rescaled to (size * height / width, size)
- interpolation (int, optional) – Desired interpolation. Default is
PIL.Image.BILINEAR
torchvision.transforms.``Scale(args*, *kwargs*) is deprecated in favor of Resize.
ToTensor
|
|
Convert a PIL Image or numpy.ndarray to tensor.
Normalize
|
|
Normalize a tensor image with mean and standard deviation. Given mean: (M1,...,Mn) and std: (S1,..,Sn) for nchannels, this transform will normalize each channel of the input torch.*Tensor i.e. input[channel] =(input[channel] - mean[channel]) / std[channel]
This transform acts out of place, i.e., it does not mutates the input tensor.
Lambda
|
|
Apply a user-defined lambda as a transform.
- lambd (function) – Lambda/function to be used for transform.
HyperParameters Search
Visualization
Pytorch in Practice
Char_Level Names Classification
|
|
There are several points needed the attention:
Input data and groundtruth
The input data should be in the size
(time_steps, batch_size, feature_dim)for the originalLSTMfunction. But if you specify the parameterbatch_firstinLSTM, then you need to switch the dimentaion to(batch_size, time_steps, feature_dim).As for the groundtruth, it should be a scalar instead of a one-hot label if we are dealing with the classification problem, whose size should be
(batch_size,1). For example, if the batch_size is 1, so one possilbility could be[1]instead of1.In this case, we usually use
CrossEntropyLossorNLLLoss.Loss function
If in the model definition we have a layer called
LogSoftmax, then we should useCrossEntropyLoss.Training function
For
LSTM, the input of shape should be[seq_len, batch, input_size], while the output shape would be[seq_len, batch, hidden_size]. And then going through a Linear layer, the output size should be[seq_len, batch, output_size]. Here theoutput_sizeis class number. But we only need the last element of output, which means output[-1,:,:]. This is because for each time step, there is always a output.Prediction
When testing, we should reshape the prediction to
[batch_size,output_size], then we can useval,idx = torch.max(prediction,1)for printing.xxx