Word embedding, i.e., vector representations of a particular word and also called word vectoring, is important in NLP. It is capable of capturing context of a word in a document, semantic and syntactic similarity, relation with other words, etc.
Word2Vec, as one of the most popular technique to learn word embeddings using shallow neural network, includes:
- 2 algorithms: continuous bag-of-words (CBOW) and skip-gram. CBOW aims to predict a center word from the surrounding context in terms of word vectors. Skip-gram does the opposite, and predicts the distribution (probability) of context words from a center word.
- 2 training methods: negative sampling and hierarchical softmax. Negative sampling defines an objective by sampling negative examples, while hierarchical softmax defines an objective using an efficient tree structure to compute probabilities for all the vocabulary.
Why do we need them?
Consider the following similar sentences: Have a good day and Have a great day. They hardly have different meaning. If we construct an exhaustive vocabulary (let’s call it V), it would have V = {Have, a, good, great, day}.
Now, let us create a one-hot encoded vector for each of these words in V. Length of our one-hot encoded vector would be equal to the size of V (=5). We would have a vector of zeros except for the element at the index representing the corresponding word in the vocabulary. That particular element would be one. The encodings below would explain this better.
Have = [1,0,0,0,0]; a=[0,1,0,0,0] ; good=[0,0,1,0,0]; great=[0,0,0,1,0] ; day=[0,0,0,0,1]( represents transpose)
If we try to visualize these encodings, we can think of a 5 dimensional space, where each word occupies one of the dimensions and has nothing to do with the rest (no projection along the other dimensions). This means ‘good’ and ‘great’ are as different as ‘day’ and ‘have’, which is not true.
Our objective is to have words with similar context occupy close spatial positions. Mathematically, the cosine of the angle between such vectors should be close to 1, i.e. angle close to 0.
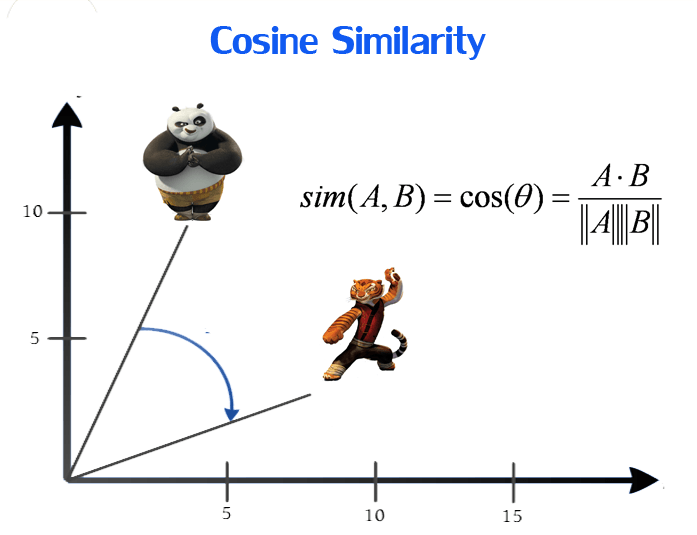
Here comes the idea of generating distributed representations. Intuitively, we introduce some dependence of one word on the other words. The words in context of this word would get a greater share of this dependence. In one hot encoding representations, all the words are independent of each other, as mentioned earlier.
How does Word2Vec work?
Word2Vec is a method to construct such an embedding. It can be obtained using two methods (both involving Neural Networks): Skip Gram and Common Bag Of Words (CBOW)
CBOW Model
This method takes the context of each word as the input and tries to predict the word corresponding to the context.
Let the input to the Neural Network be the word, great. Notice that here we are trying to predict a target word (day) using a single context input word great. More specifically, we use the one hot encoding of the input word and measure the output error compared to one hot encoding of the target word (day). In the process of predicting the target word, we learn the vector representation of the target word.
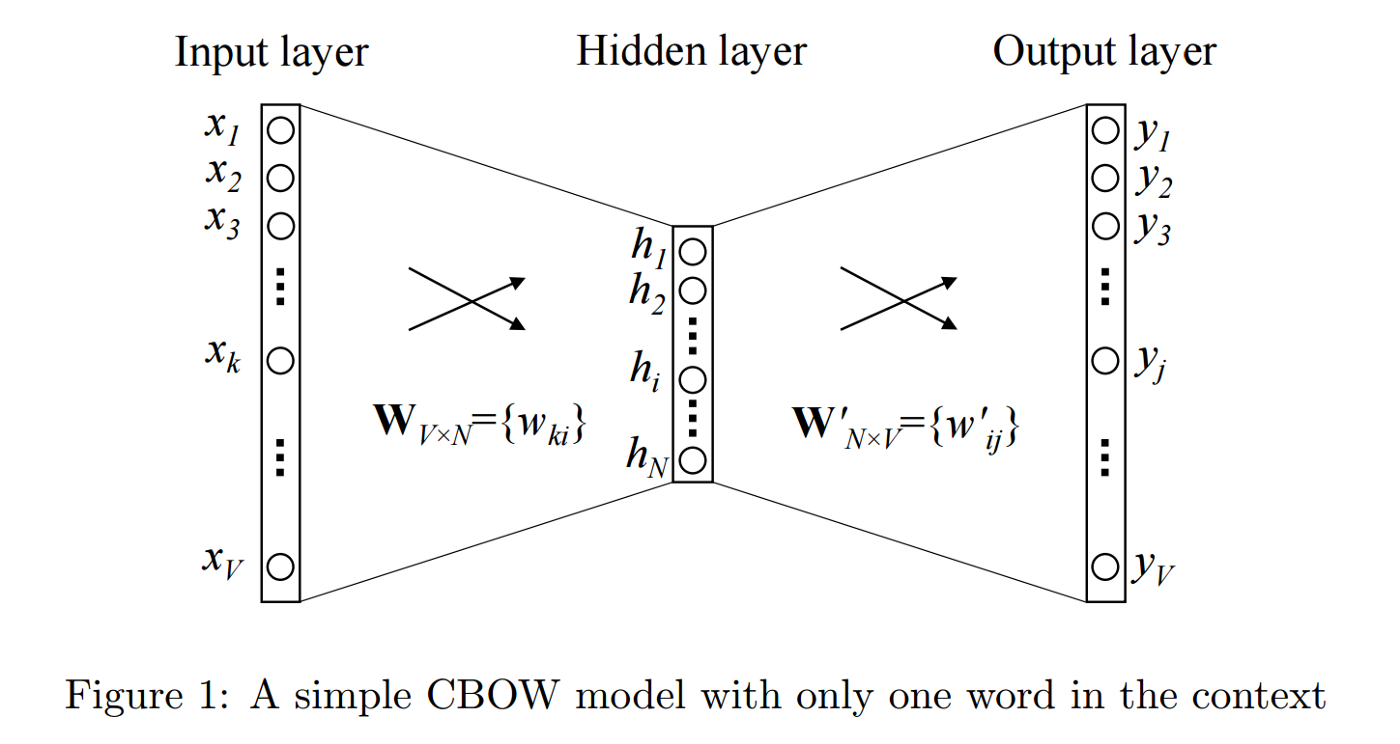
Note: input is the one-hot vector of one word.
The input or the context word is a one hot encoded vector of size V. The hidden layer contains N neurons and the output is again a V length vector with the elements being the softmax values.
The hidden layer neurons just copy the weighted sum of inputs to the next layer. There is no activation like sigmoid, tanh or ReLU. The only non-linearity is the softmax calculations in the output layer.
But, the above model used a single context word to predict the target. We can use multiple context words to do the same.
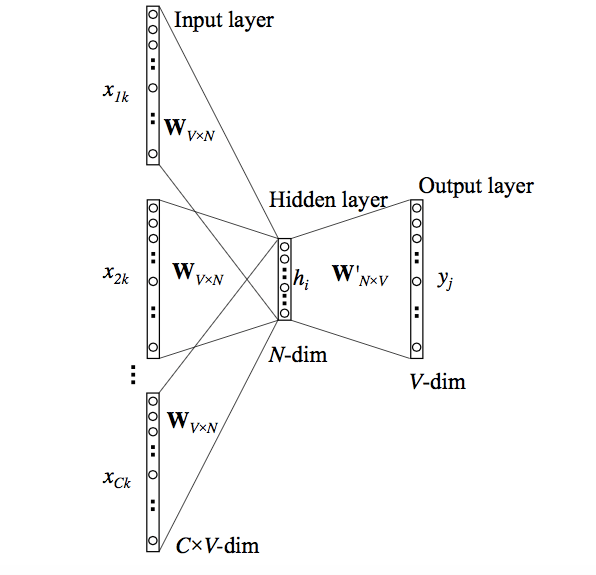
Skip-Gram Model
We can use the target word (whose representation we want to generate) to predict the context and in the process, we produce the representations.
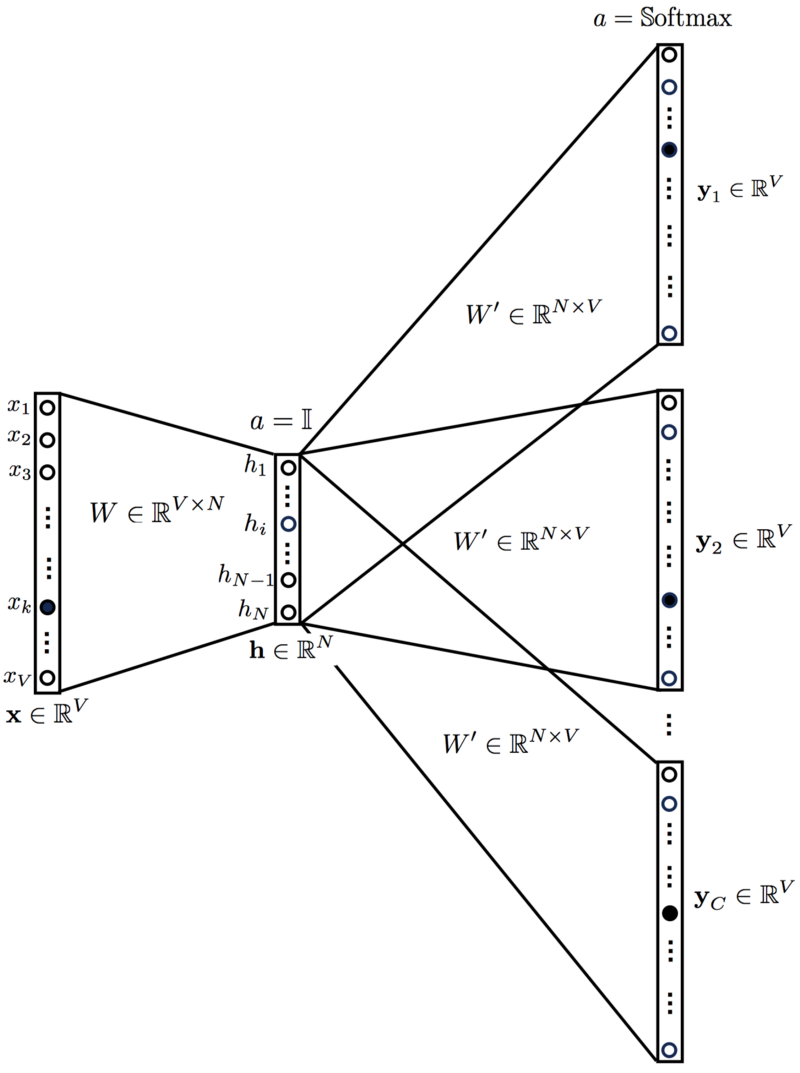
We input the target word into the network. The model outputs C probability distributions. What does this mean? For each context position, we get C probability distributions of V probabilities, one for each word.
The Hidden Layer
For our example, we’re going to say that we’re learning word vectors with 300 features. So the hidden layer is going to be represented by a weight matrix with 10,000 rows (one for every word in our vocabulary) and 300 columns (one for every hidden neuron).
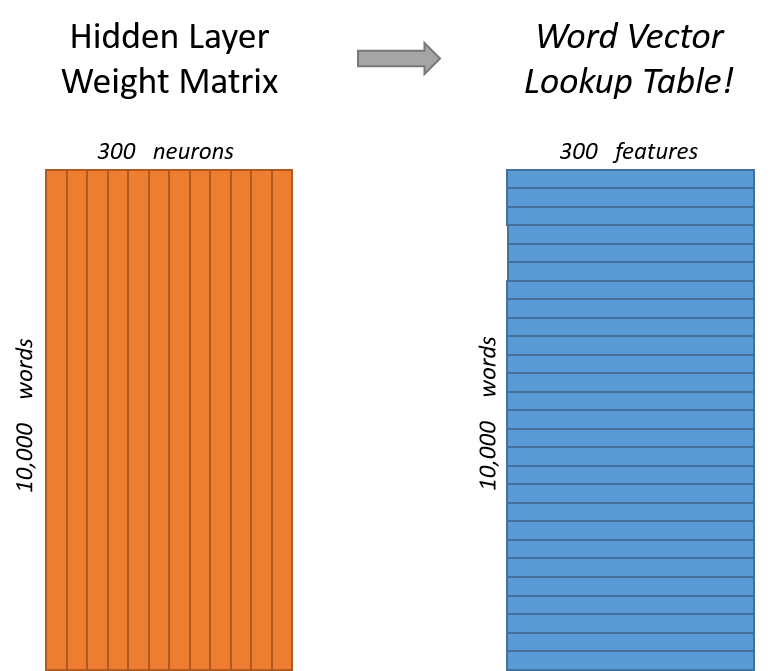
So the end goal of all of this is really just to learn this hidden layer weight matrix – the output layer we’ll just toss when we’re done!
Now, you might be asking yourself–“That one-hot vector is almost all zeros… what’s the effect of that?” If you multiply a 1 x 10,000 one-hot vector by a 10,000 x 300 matrix, it will effectively just select the matrix row corresponding to the “1”. Here’s a small example to give you a visual.

This means that the hidden layer is operating as a lookup table. The output of the hidden layer is just the “word vector” for the input word.
Intuition
Ok, are you ready for an exciting bit of insight into this network?
If two different words have very similar “contexts” (that is, what words are likely to appear around them), then our model needs to output very similar results for these two words. And one way for the network to output similar context predictions for these two words is if the word vectors are similar. So, if two words have similar contexts, then our network is motivated to learn similar word vectors for these two words! Ta da!
say we have two words, their word embedding are A and B. The hidden-output weight matrix is
HO, so the outputs areA*HOandB*HO. Because these two words have similar contexts, so the groundtruth target should be same. which result inA*HO = B*HO, meaningAandBhave to be similar.
And what does it mean for two words to have similar contexts? I think you could expect that synonyms like “intelligent” and “smart” would have very similar contexts. Or that words that are related, like “engine” and “transmission”, would probably have similar contexts as well.
This can also handle stemming for you – the network will likely learn similar word vectors for the words “ant” and “ants” because these should have similar contexts.
Loss Function
Say we have a word documents with $T$ words, our task is to predict context words within a window of fixed size $m$, given center word $w_j$:
to simplify it:
Here, we transform max to min by put a negative sign in front of the formula.
In order to calculate $P\left(w_{t+j} | w_{t} ; \theta\right)$, we need to introduce two vectors for each word in the document:
- $v_w$ when $w$ is a center word
- $u_w$ when $w$ is a context word
Then for a center word $c$ and a context word $o$:
which equals the softmax function if we take $x_i=u_{o}^{T} v_{c}$,
The softmax function maps arbitrary values $x_i$ to a probability distribution $p_i$,
- “max” because amplifies probability of largest $x_i$,
- “soft” because still assigns some probability to smaller $x_i$
Gradient
Say we want to calculate the derivative of center vector $v_c$,
Here $\sum_{w\in V}P(o|center)u_w$ is the expected context word by our trained model, and $u_o$ is our target context, it is like the difference between the target and prediction.
We can treat $u_0$ as we choose the target row from contect matrix $U$, which is $U^T\cdot y$; as for $u_w$, we can see it as we also choose a row from context matrix, but which row? Actually, it is each row of the matrix and average them. Because $P(o|c)$ is the prediction, which is the output of our model, so we can treat it as $\hat y$. Therefor $\sum_{w\in V}P(o|c)u_w=U^T \cdot \hat y$ , so the gradient for center word vector is:
where $U$ is one of the learned weights.
Then we need to calculate the derivative for context vector $u_w$:
if $w=o$, then:
if $w \ne o$,
Similarly, we can combine $P(O=o | C=c)-1$ and $P(O=o | C=c)$ as $\hat y - y$,
Negative sampling
You may have noticed that the skip-gram neural network contains a huge number of weights… For our example with 300 features and a vocab of 10,000 words, that’s 3M weights in the hidden layer and output layer each! Training this on a large dataset would be prohibitive.
The main idea of negative sampling is to train binary logistic regressions for a true pair (center word and word in its context window) versus several noise pairs (the center word paired with a random word)
Negative sampling addresses this by having each training sample only modify a small percentage of the weights, rather than all of them. Here’s how it works.
Assume that $K$ negative samples (words) are drawn from the vocabulary. For simplicity of notation we shall refer to them as $w_1,w_2,..,w_k$ and their outside vectors as $u_1,u_2,…,u_k$. Note that $o \notin \{w_1,w_2,…,w_k\}$. For a center word $c$ and an outside word $o$, the negative sampling loss function is given by:
for a sample $w_1,…,w_k$, where $\sigma(\cdot)$ is the sigmoid function. The idea is to maximize probability that real outside word appears, minimize prob. that random words appear around center word.
Gradient
For center word vector $v_c$:
For outside target word vector $u_o$:
For sampling outside word vector $u_w$:
Numpy Implementation
|
|
|
|
|
|
Reference
Introduction to Word Embedding and Word2Vec
Word2Vec Tutorial - The Skip-Gram Model
An Intuitive Understanding of Word Embeddings: From Count Vectors to Word2Vec - calculation examples