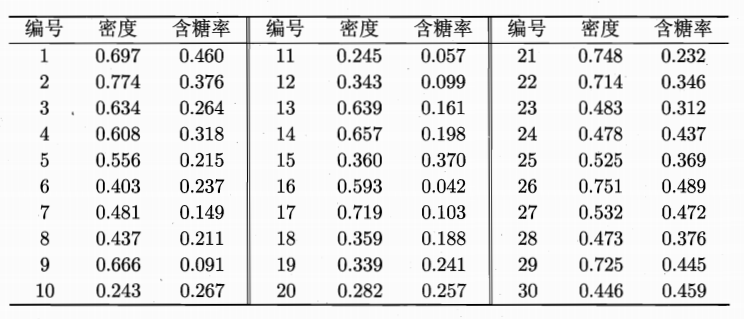
肉
土豆炖排骨
材料
排骨,土豆,豆瓣酱,酱油,料酒,姜末,大料,花椒
步骤
- 将剁成小块的猪排骨用沸水焯变色,洗去待用,郫县豆瓣酱剁碎待用
- 土豆去皮切成小块,用清水浸泡片刻,除去变面淀粉
- 锅中放入1大匙(15ml)油烧热,将土豆放入煎至金黄,盛出待用
- 炒锅烧热,放入2大匙(30ml)油,放入焯过水的排骨炒至金黄
- 放入剁碎的豆瓣酱和姜末炒匀,炒出香味,加入酱油、料酒炒匀
- 加入适量开水(没过排骨),烧开,加入大料和花椒,加盖转小火烧20分钟至排骨酥烂
- 加入煎黄的土豆块,烧5分钟至汤汁收干,用盐、糖、蚝油调味即可
-
土豆炖牛肉
材料
牛肉(牛腩),土豆,洋葱,胡萝卜,葱姜,老抽,料酒,醋,糖,番茄沙司,黑胡椒,油 盐
步骤
- 牛肉切块冷水下锅焯2分钟,全程用温水清洗干净,
- 锅放油烧热,先下牛肉煸炒一下,烹人老抽,料酒和一小勺白醋,
- 接着下洋葱西红柿,撒一勺白糖继续翻炒,
- 挤人番茄沙司(多挤一些),再磨一些胡椒粒炒匀,
- 放葱姜,倒入足够的热水,中大火烧20分钟改小火炖1小时左右,
- 出锅前放土豆胡萝卜块加盐烧熟,等到肉烂,汤汁粘稠就可以调味出锅了。
鱼香肉丝
材料
食材:肉、胡萝卜、青椒、黑木耳
步骤
- 使用盐、胡椒粉、料酒、蛋清和淀粉腌制肉10min
- 白糖、香醋、料酒、酱油、(盐)、微量清水、淀粉兑成芡汁
- 下油炒肉至变色,再入胡萝卜,入豆瓣酱于一边炒出红油,下葱姜蒜末炒熟
- 下肉丝,最后倒入兑好的芡汁炒均匀出锅
饭
土豆焖饭
材料
米、土豆、蒜、料酒、豆瓣酱、老抽、生抽、糖、葱、香油。
步骤
- 土豆削皮切小块,泡在清水里防止氧化,待下锅前在沥干
- 炒锅入油,油烧热后倒入大蒜片爆香,倒入沥干后的土豆块,翻炒至边角边边略略焦黄,转小火,放入豆瓣酱炒香,再加入料酒、生抽、老抽、糖翻炒均匀上色,关火(这个时候土豆还是生的,不用炒熟)
- 把炒过的土豆、大蒜片都倒进生米里,盖上电饭煲,煮饭模式
- 饭煮好后开盖把土豆和饭轻轻搅匀,撒入葱花,焖10分钟,准备盛出时放一些鸡精和香油拌匀即可。
蔬菜
金针菇日本豆腐
材料
日本豆腐,金针菇,大葱,蒜,盐,酱油,耗油。
步骤
- 日本豆腐横切成块,
- 锅中倒油烧热,加入日本豆腐煎至表皮焦黄,沥干捞起。剩下的油再加入蒜以及大葱爆香,加入金针菇,
- 翻炒至金针菇软身,加入一勺酱油,一勺耗油翻炒均匀后加入日本豆腐在金针菇上面,此时再加入一勺酱油及耗油覆盖豆腐上面,盖上盖焖几分钟(2分钟左右)
- 打开锅盖,倒入芡汁,略微翻均匀,再盖上焖一小会儿,待汁收得差不多。