Object detection is one of the popular computer vision tasks, i.e., image classification, object detection, object tracking, image segmentation, image caption and image generation. The main of object detection is to find out all the objects in a image, their positions and corresponding confidence.
In brief, in order to detect objects, we first need to generate region proposals, then to classify the object class and detect the bounding box.
R-CNN
- First, R-CNN uses selective search by [2] to generate about 2K region proposals, i.e. bounding boxes for image classification.
- Then, for each bounding box, image classification is done through CNN.
- Finally, each bounding box can be refined using regression.
Faster R-CNN
It is the first fully differentiable object-detection model that was proposed.
In Faster R-CNN, RPN using SS is replaced by RPN using CNN. And this CNN is shared with detection network. This CNN can be ZFNet or VGGNet in the paper.** Thus, the overall network is as below:
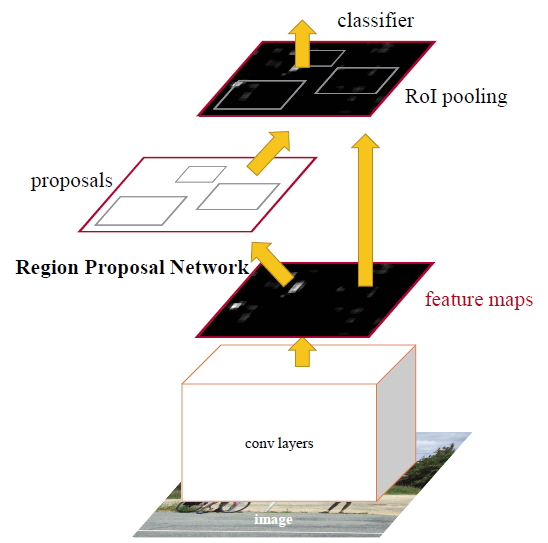
- First, the picture goes through conv layers and feature maps are extracted.
- Then a sliding window is used in RPN for each location over the feature map.
- For each location, k (k=9) anchor boxes are used (3 scales of 128, 256 and 512, and 3 aspect ratios of 1:1, 1:2, 2:1) for generating region proposals.
- A cls layer outputs 2k scores whether there is object or not for k boxes.
- A reg layer outputs 4k for the coordinates (box center coordinates, width and height) of k boxes.
- With a size of W**×**H feature map, there are WHk anchors in total.
YOLO ref
The obove object detection methods are usually two-stage detectot.
- In R-CNN and Faster R-CNN, an object detector that required an algorithm such as Selective Search (or equivalent) is used to propose candidate bounding boxes that could contain objects.
- These regions were then passed into a CNN for classification, ultimately leading to one of the first deep learning-based object detectors.
The problem with the standard R-CNN method was that it was painfully slow and not a complete end-to-end object detector. Until the proposal of Faster R-CNN, which is an end-to-end deep learning framework
While R-CNNs tend to very accurate, the biggest problem with the R-CNN family of networks is their speed — they were incredibly slow. To help increase the speed of deep learning-based object detectors, both Single Shot Detectors (SSDs) and YOLO use a one-stage detector strategy. These algorithms treat object detection as a regression problem, taking a given input image and simultaneously learning bounding box coordinates and corresponding class label probabilities.
In general, single-stage detectors tend to be less accurate than two-stage detectors but are significantly faster.
A great explanation about YOLO.
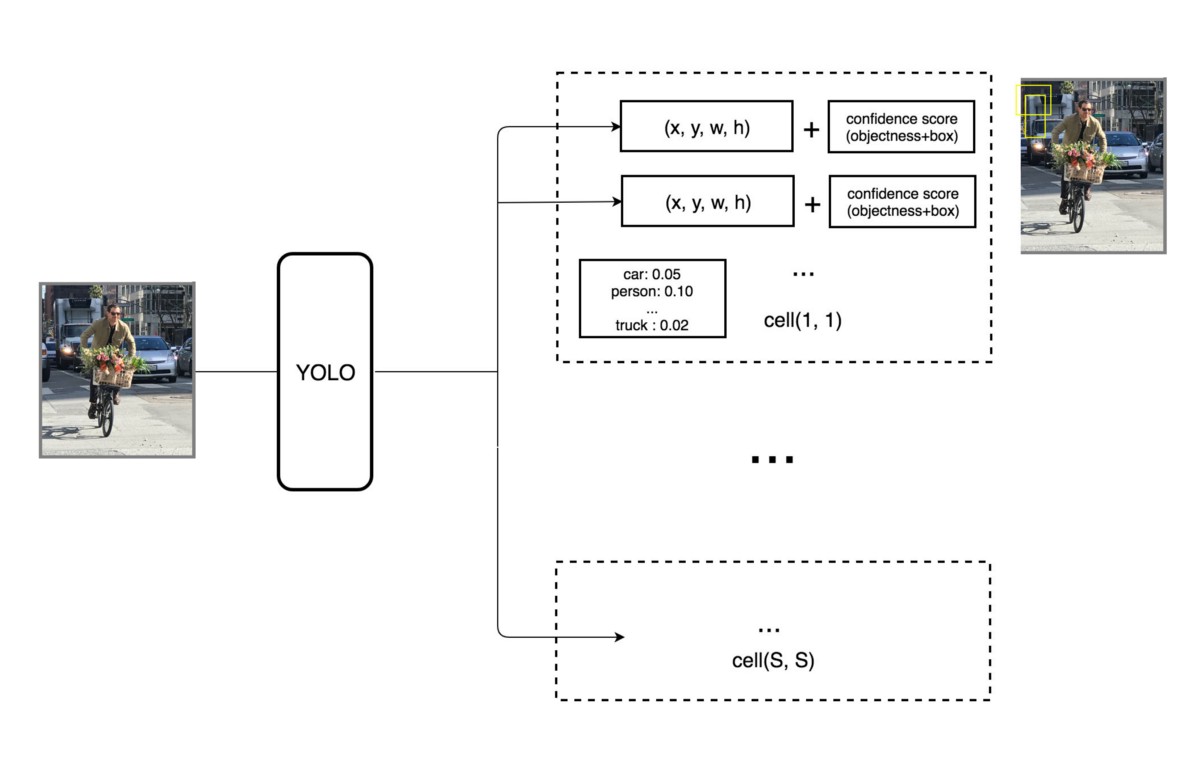

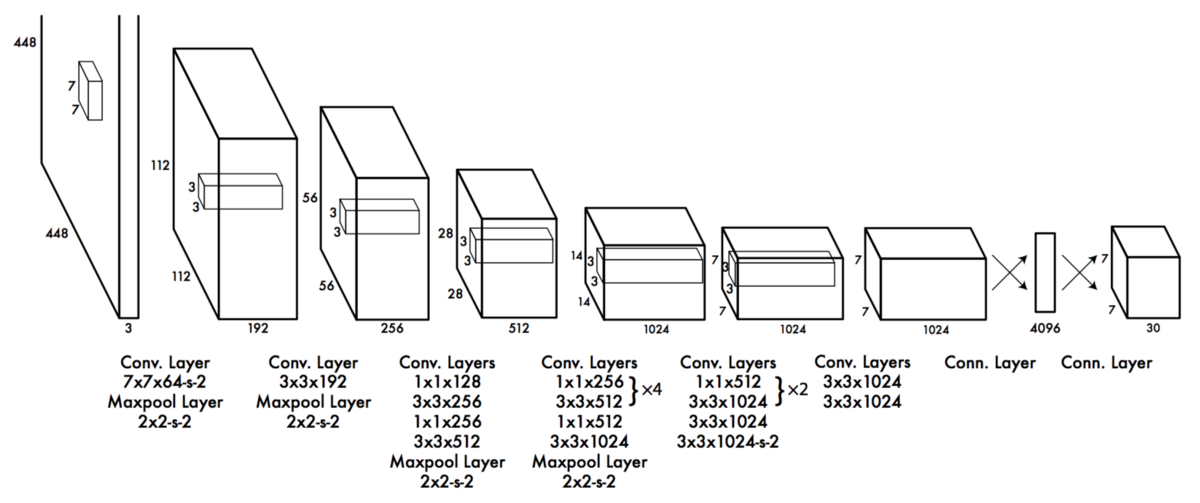
Some convolution layers use $1 \times 1$ reduction layers alternatively to reduce the depth of the features maps.
A comprehensive review Real-time Object Detection with YOLO, YOLOv2 and now YOLOv3.
How to implement a YOLO (v3) object detector from scratch in PyTorch
References
Review: Faster R-CNN (Object Detection)
Faster R-CNN: Down the rabbit hole of modern object detection