If you’ve ever worked on a project for deep learning for NLP, you’ll know how painful and tedious all the preprocessing is. Before you start training your model, you have to:
- Read the data from disk
- Tokenize the text
- Create a mapping from word to a unique integer
- Convert the text into lists of integers
- Load the data in whatever format your deep learning framework requires
- Pad the text so that all the sequences are the same length, so you can process them in batch
Torchtext is a library that makes all the above processing much easier.
In this post, I’ll demonstrate how torchtext can be used to build and train a text classifier from scratch.To make this tutorial realistic, I’m going to use a small sample of data from this Kaggle competition. The data and code are available in GitHub repo, so feel free to clone it and follow along. Or, if you just want to see the minimal working example, feel free to skip the rest of this tutorial and just read the notebook.
The Overview
Torchtext follows the following basic formula for transforming data into working input for your neural network:
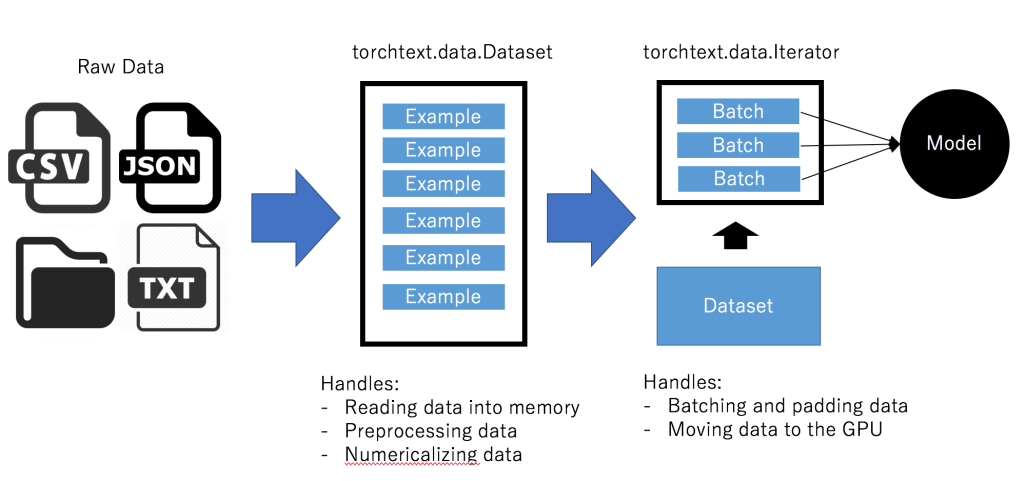
Torchtext takes in raw data in the form of text files, csv/tsv files, json files, and directories (as of now) and converts them to Datasets. Datasets are simply preprocessed blocks of data read into memory with various fields.
Torchtext then passes the Dataset to an Iterator. Iterators handle numericalizing, batching, packaging, and moving the data to the GPU. Basically, it does all the heavy lifting necessary to pass the data to a neural network.
In the following sections, we’ll see how each of these processes plays out in an actual working example.
Declaring the Fields
Torchtext takes a declarative approach to loading its data: you tell torchtext how you want the data to look like, and torchtext handles it for you.
The way you do this is by declaring a Field. The Field specifies how you want a certain (you guessed it) field to be processed. Let’s look at an example:
|
|
In the toxic comment classification dataset, there are two kinds of fields: the comment text and the labels (toxic, severe toxic, obscene, threat, insult, and identity hate).
Let’s look at the LABEL field first, since it’s simpler. All fields, by default, expect a sequence of words to come in, and they expect to build a mapping from the words to integers later on (this mapping is called the vocab, and we will see how it is created later). If you are passing a field that is already numericalized by default and is not sequential, you should pass use_vocab=False and sequential=False.
For the comment text, we pass in the preprocessing we want the field to do as keyword arguments. We give it the tokenizer we want the field to use, tell it to convert the input to lowercase, and also tell it the input is sequential.
In addition to the keyword arguments mentioned above, the Field class also allows the user to specify special tokens (the unk_token for out-of-vocabulary words, the pad_token for padding, the eos_token for the end of a sentence, and an optional init_token for the start of the sentence), choose whether to make the first dimension the batch or the sequence (the first dimension is the sequence by default), and choose whether to allow the sequence lengths to be decided at runtime or decided in advance. Fortunately, the docstrings for the Field class are relatively well written, so if you need some advanced preprocessing you should refer to them for more information.
The field class is at the center of torchtext and is what makes preprocessing such an ease. Aside from the standard field class, here’s a list of the fields that are currently available (along with their use cases):
| Name | Description | Use Case |
|---|---|---|
| Field | A regular field that defines preprocessing and postprocessing | Non-text fields and text fields where you don’t need to map integers back to words |
| ReversibleField | An extension of the field that allows reverse mapping of word ids to words | Text fields if you want to map the integers back to natural language (such as in the case of language modeling) |
| NestedField | A field that takes processes non-tokenized text into a set of smaller fields | Char-based models |
| LabelField (New!) | A regular field with sequential=False and no |
Label fields in text classification. |
Constructing the Dataset
The fields know what to do when given raw data. Now, we need to tell the fields what data it should work on. This is where we use Datasets.
There are various built-in Datasets in torchtext that handle common data formats. For csv/tsv files, the TabularDataset class is convenient. Here’s how we would read data from a csv file using the TabularDataset:
|
|
For the TabularDataset, we pass in a list of (name, field) pairs as the fields argument. The fields we pass in must be in the same order as the columns. For the columns we don’t use, we pass in a tuple where the field element is None
The splits method creates a dataset for the train and validation data by applying the same processing. It can also handle the test data, but since out test data has a different format from the train and validation data, we create a different dataset.
Datasets can mostly be treated in the same way as lists. To understand this, it’s instructive to take a look inside our Dataset. Datasets can be indexed and iterated over like normal lists, so let’s see what the first element looks like:
|
|
we get an Example object. The Example object bundles the attributes of a single data point together. We also see that the text has already been tokenized for us, but has not yet been converted to integers. This makes sense since we have not yet constructed the mapping from words to ids. Constructing this mapping is our next step.
Torchtext handles mapping words to integers, but it has to be told the full range of words it should handle. In our case, we probably want to build the vocabulary on the training set only, so we run the following code:
|
|
This makes torchtext go through all the elements in the training set, check the contents corresponding to the TEXT field, and register the words in its vocabulary. Torchtext has its own class called Vocab for handling the vocabulary. The Vocab class holds a mapping from word to id in its stoiattribute and a reverse mapping in its itos attribute. In addition to this, it can automatically build an embedding matrix for you using various pretrained embeddings like word2vec. The Vocab class can also take options like max_size and min_freq that dictate how many words are in the vocabulary or how many times a word has to appear to be registered in the vocabulary. Words that are not included in the vocabulary will be converted into
Here is a list of the currently available set of datasets and the format of data they take in:
| Name | Description | Use Case |
|---|---|---|
| TabularDataset | Takes paths to csv/tsv files and json files or Python dictionaries as inputs. | Any problem that involves a label (or labels) for each piece of text |
| LanguageModelingDataset | Takes the path to a text file as input. | Language modeling |
| TranslationDataset | Takes a path and extensions to a file for each language. e.g. If the files are English: “hoge.en”, French: “hoge.fr”, path=”hoge”, exts=(“en”,”fr”) | Translation |
| SequenceTaggingDataset | Takes a path to a file with the input sequence and output sequence separated by tabs. 2 | Sequence taggingNow that we have our data formatted and read into memory, we turn to the next step: creating an Iterator to pass the data to our model. |
Now that we have our data formatted and read into memory, we turn to the next step: creating an Iterator to pass the data to our model.
Constructing the Iterator
In torchvision and PyTorch, the processing and batching of data is handled by DataLoaders. For some reason, torchtext has renamed the objects that do the exact same thing to Iterators. The basic functionality is the same, but Iterators, as we will see, have some convenient functionality that is unique to NLP.
Below is code for how you would initialize the Iterators for the train, validation, and test data.
|
|
Update: The sort_within_batch argument, when set to True, sorts the data within each minibatch in decreasing order according to the sort_key. This is necessary when you want to use pack_padded_sequence with the padded sequence data and convert the padded sequence tensor to a PackedSequenceobject.
The BucketIterator is one of the most powerful features of torchtext. It automatically shuffles and buckets the input sequences into sequences of similar length.
The reason this is powerful is that – as I mentioned earlier – we need to pad the input sequences to be of the same length to enable batch processing. For instance, the sequences
|
|
would need to be padded to become
|
|
As you can see, the amount of padding necessary is determined by the longest sequence in the batch. Therefore, padding is most efficient when the sequences are of similar lengths. The BucketIterator does all this behind the scenes. As a word of caution, you need to tell the BucketIterator what attribute you want to bucket the data on. In our case, we want to bucket based on the lengths of the comment_text field, so we pass that in as a keyword argument. See the code above for details on the other arguments.
For the test data, we don’t want to shuffle the data since we’ll be outputting the predictions at the end of training. This is why we use a standard iterator.
Here’s a list of the Iterators that torchtext currently implements:
| Name | Description | Use Case |
|---|---|---|
| Iterator | Iterates over the data in the order of the dataset. | Test data, or any other data where the order is important. |
| BucketIterator | Buckets sequences of similar lengths together. | Text classification, sequence tagging, etc. (use cases where the input is of variable length) |
| BPTTIterator | An iterator built especially for language modeling that also generates the input sequence delayed by one timestep. It also varies the BPTT (backpropagation through time) length. This iterator deserves its own post, so I’ll omit the details here. | Language modeling |
Wrapping the Iterator
Currently, the iterator returns a custom datatype called torchtext.data.Batch. The Batch class has a similar API to the Example type, with a batch of data from each field as attributes. Unfortunately, this custom datatype makes code reuse difficult (since each time the column names change, we need to modify the code), and makes torchtext hard to use with other libraries for some use cases (like torchsample and fastai).
Concretely, we’ll convert the batch to a tuple in the form (x, y) where x is the independent variable (the input to the model) and y is the dependent variable (the supervision data). Here’s the code:
|
|
All we’re doing here is converting the batch object to a tuple of inputs and outputs.
Training the Model
We’ll use a simple LSTM to demonstrate how to train the text classifier on the data we’ve built:
|
|
Now, we’ll write the training loop. Thanks to all our preprocessing, this is very simple. We can iterate using our wrapped Iterator, and the data will automatically be passed to us after being moved to the GPU and numericalized appropriately.
|
|
There’s not much to explain here: this is just a standard training loop. Now, let’s generate our predictions
|
|
Finally, we can write our predictions to a csv file.
|
|
And we’re done! We can submit this file to Kaggle, try refining our model, changing the tokenizer, or whatever we feel like, and it will only take a few changes in the code above.
Reference
A Comprehensive Introduction to Torchtext (Practical Torchtext part 1)
Language modeling tutorial in torchtext (Practical Torchtext part 2)