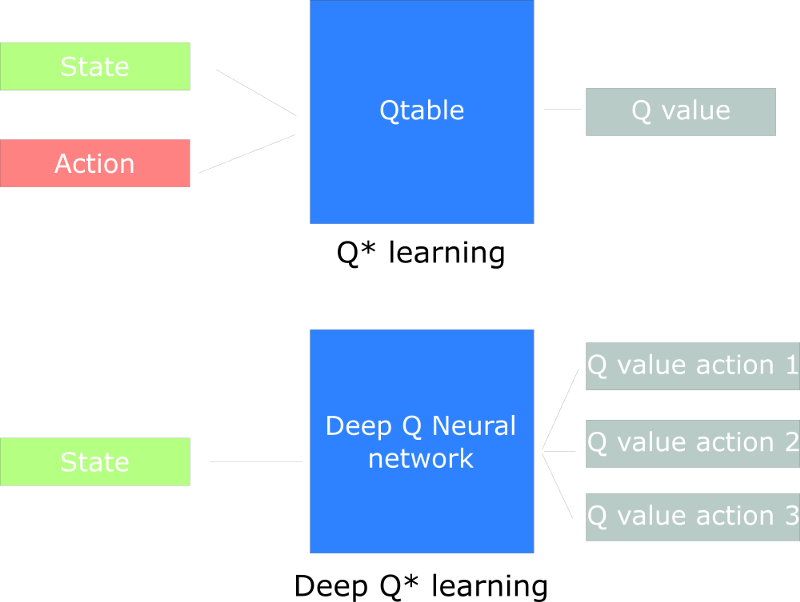
Q-Learning needs to maintain a Q-table that an agent uses to find the best action to take given a state. However, producing and updating a Q-table can become ineffective in big state space environments. While in this post, we are going to create a Deep Q Neural Network to improve Q Learning. Instead of using a Q-table, we’ll implement a Neural Network that takes a state and approximates Q-values for each action based on that state. ref