用于分类任务的逻辑斯蒂回归。
Python Sth
EasyDict
|
|
目录
检查目录,并生成一级目录
|
|
多级目录生成
|
|
R & W in TXT
np.loadtxt()用于从文本加载数据。 文本文件中的每一行必须含有相同的数据。
|
|
- fname:文件名
- dtype:数据类型,默认float
- comments:注释
- delimiter:分隔符,默认是空格
- skiprows:跳过前几行,0是第一行,必须int
usecols:要读取哪些列,0是第一列。例如,usecols = (1,4,5)将提取第2,第5和第6列。默认读取所有列。unpack如果为True,将分列读取。
|
|
TXT追加内容
|
|
文件操作
文件移动
|
|
pprint
it is used for pretty-print data structures.
Random
np.random.rand()
|
|
- rand函数根据给定维度生成[0,1)之间的数据,包含0,不包含1
- dn为每个维度
- 返回值为指定维度的数组
np.random.randn()
- randn函数返回具有标准正态分布的数据。
- dn为每个维度
- 返回值为指定维度的数组
np.random.randint()
numpy.random.randint(low, high, size)
- 返回开区间 [low, high)范围内的整数值
- 默认high是None,如果只有low,那范围就是[0,low)。如果有high,范围就是[low,high)
- size是输出数组的维度(形状),可以是列表,或者元组
np.random.choice()
numpy.random.choice(a, size)
- a可以是一个数或者一个array,如果是一个数则sample范围是【0,a);如果是array,则从中sample
- size为sample大小;如果size=(m,n,k),则采样$mnk$个。
String
数字补0
|
|
Plt
图片保存去除周边空白ref
|
|
bbox_inches =’tight’ 只能用于保存图片,不能用于显示。
Time
|
|
Zip
|
|
|
|
How to unzip?
Unzipping means converting the zipped values back to the individual self as they were. This is done with the help of “*” operator.
|
|
|
|
Parser
|
|
|
|
Matplotlib
5 Quick and Easy Data Visualizations in Python with Code
8 of the best articles on visualizing data
ElementTree
!!!!!所有的输入都必须是字符串!!!!!
|
|

Naming style
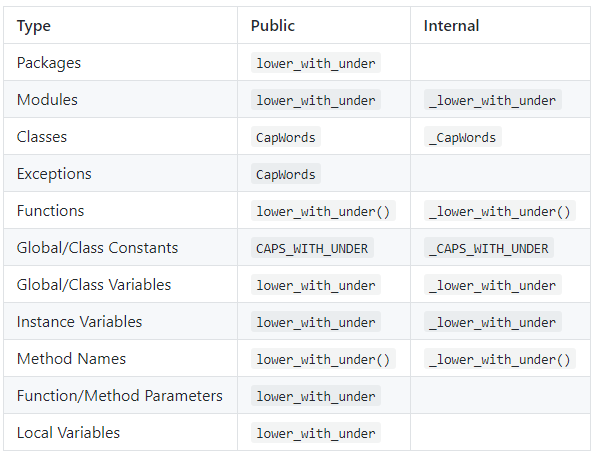
Adversarial AutoEncoder
Adversarial Autoencoder
无监督AAE
autoencoder中的encoder的输出(潜在码)并不能在某一特定空间均匀分布,而且AE 的 G 只能保证将由 x 生成的 z 还原为 x。如果我们随机生成 1 个 z,经过 AE 的 G 后往往不会得到有效的图像。
所以我们希望encoder的输出可以服从某一分布,这个分布可以是正态分布,均匀分布等,这样就会使encoder的输出均匀分布在给定的先验分布,使decoder学习到一个先验分布到输入数据的映射(本例中就是学习到MNIST手写体数据的分布),那么此时只需从这个先验分布采样出 z,就能通过 G 得到有效的图像。
假设你正在学习一门课程,如果你的老师并没有提供任何资料,你又会如何学习这门课呢?但是考试怎么办呢,难道要自己瞎答吗?这种情况就是类似我们的encoder的输出并不服从某种特定分布,这样decoder就无法学习到一个从任意数字到图片的映射。
但是如果你有了一个课程指导书,你就可以在考试之前复习这本书,这样就知道了可能的考试内容。类似的,如果我们的encoder输出服从一个已知分布,那么encoder就会将潜在码覆盖整个先验分布。
模型
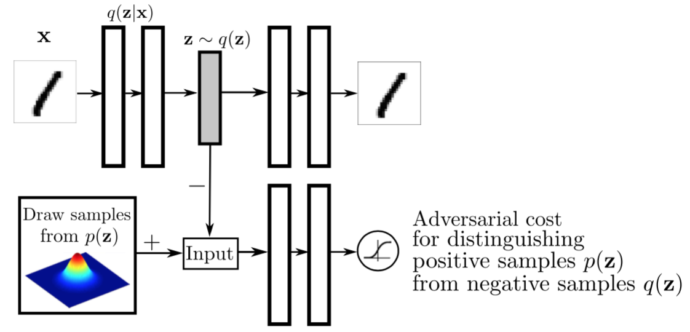

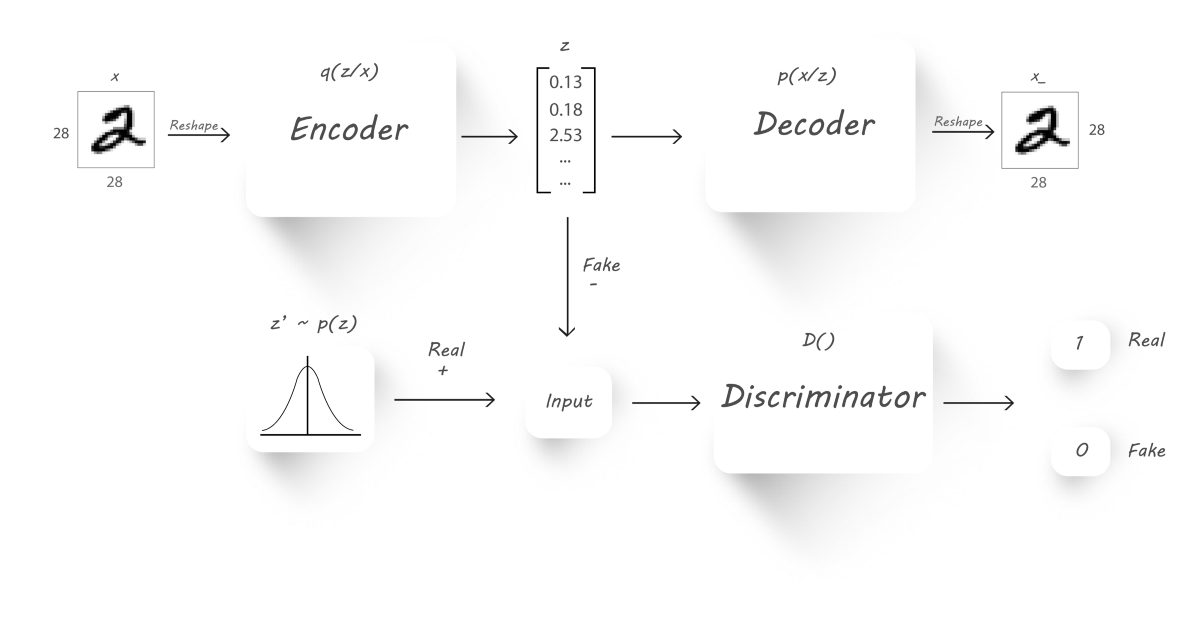
- $x$是输入
- $q(z|x)$是encoder基于输入$x$的输出
- $z$是潜在码,同时也是一个假输入,从$q(z|x)$中采样得到
- $z’$是采样自想要的分布,作为真实输入
- $p(x|z)$是基于$z$的decoder输入
- $x_$是重构图像
我们的主要目的是迫使encoder的输出逼近一个先验分布(比如正态分布,gamma分布等)。我们将使用encoder$(q(z|x))$作为生成器,而判别器辨别它的输入是来自于一个先验分布$p(z)$,亦或是来自于encoder的输出$z$,decoder仍然进行图片重构的工作。
训练
AAE的训练分成两个部分:重构阶段和正则化阶段。
训练上述模型,分成两个阶段:一个是对辨别器的训练;另一个是对GAN模型的训练。
对于分辨器,其输入就是真假latent code,输出real概率
对于GAN模型,它需要配合分辨器来完成训练。encoder-decoder产生两个输出:一个是latent code,一个是image,但是我们只需要latent code作为分辨器的输入,从而完成GAN模型的训练。
重构阶段
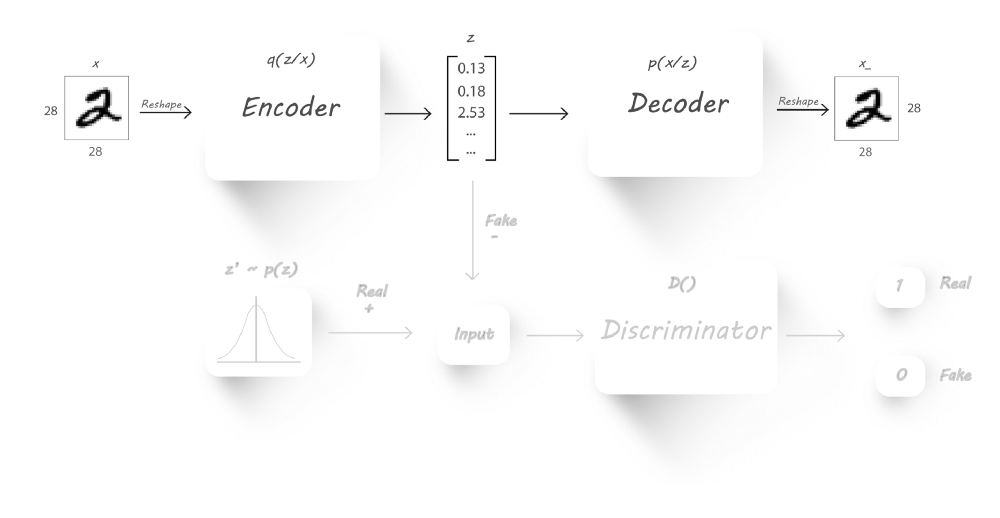
在该阶段,我们需要训练encoder和decoder来最小化重构误差(输入图片与重构图片间的均方误差)。我们将输入传递给encoder,encoder输出一个潜在码;随后,我们将该潜在码送入decoder从而得到一张重构图像。
正则化阶段
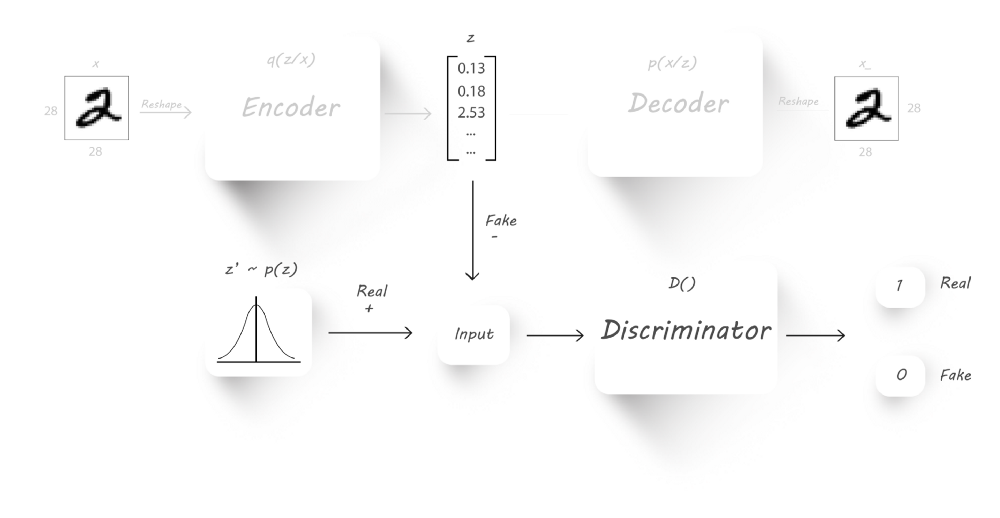
在该阶段,我们训练生成器和辨别器,我们将encod的输出$z$和随机采样$z’$(来自于想要的分布)作为输入来训练辨别器,这样辨别器就会返回1如果输入是$z’$,而返回0如果输入是$z$。接下来,为了迫使encoder的输出$z$逼近我们想要的分布,我们将encoder的输出作为辨别器的输入,连接encoder和辨别器。
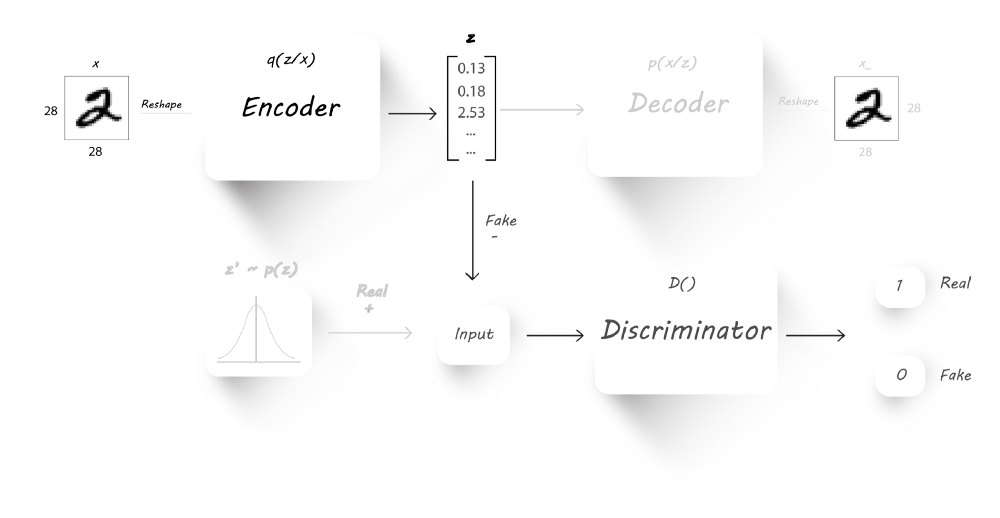
我们固定辨别器的权重参数,固定输入的目标标签为1,然后我们输入一些图像到encoder,并计算辨别器的输出与目标标签间的差异(使用交叉熵损失函数),这个阶段我们只更新encoder的权重参数,这样促使encoder去学习我们想要的分布,使输出服从这个分布。
Python实现
Encoder构造
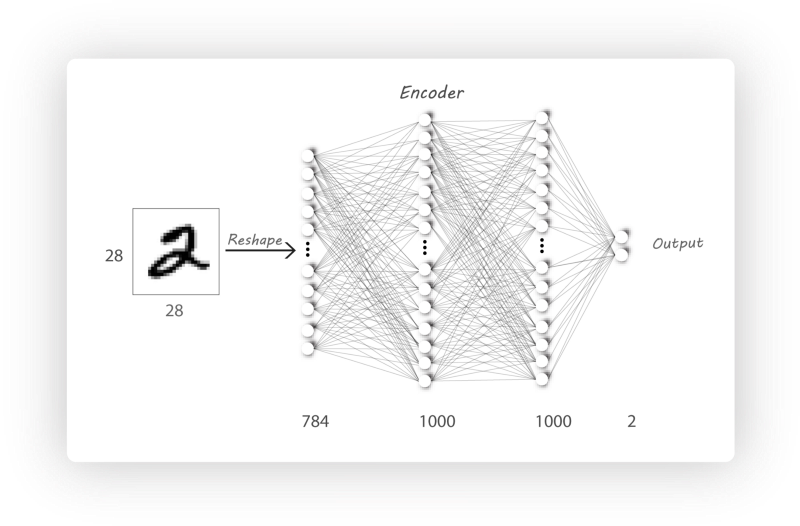
|
|
|
|
Decoder构造
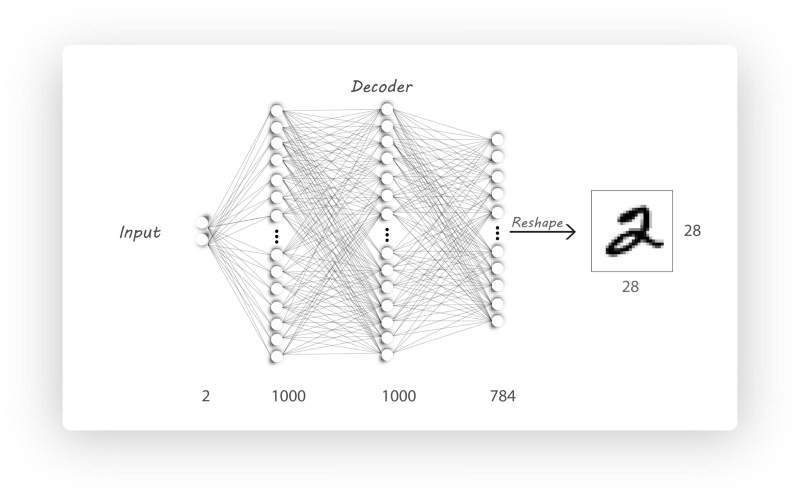
|
|
Discriminator构造
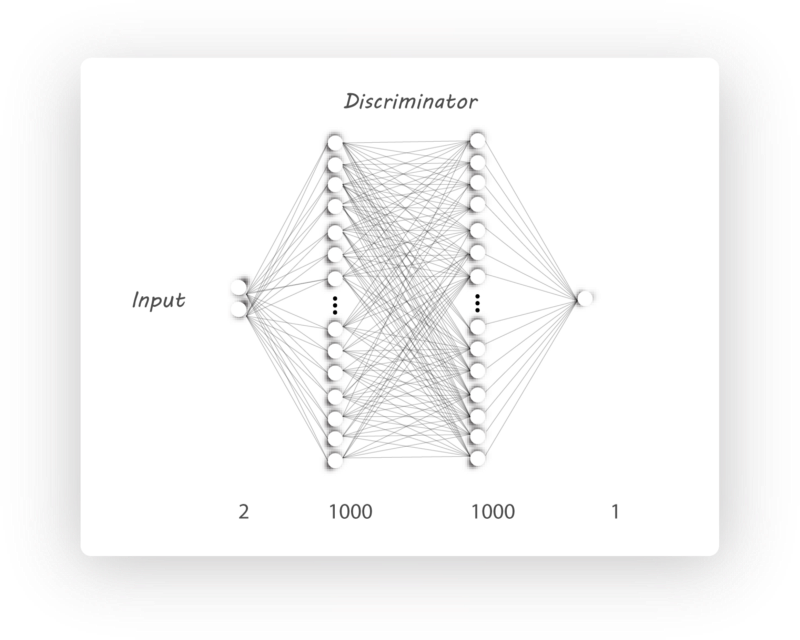
|
|
GAN的构造与编译
|
|
|
|
|
|
监督AAE
Disentanglement of style and content
对于一个写作主题,每一个人写出来的文章都有不同的内容(content)和字体(style)。对于MNIST字体,可以发现它的所有图像都有一样的style,所以我们想要从这个数据集中学习MNIST字体的style。为了更明确content和style的区别,我们有如下图:
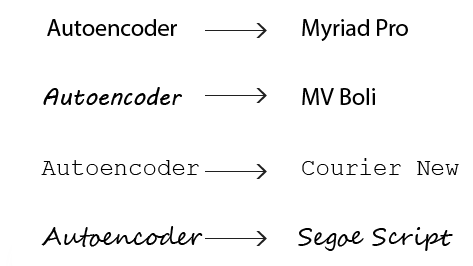
每个文本都有相同的content “Autoencoder”,但是它们的字体是不一样的,现在我们想要从图片中去区分style(Myriad Pro, MV Boil,…)和content,特征分离是表征学习(representation learning)的一个重要内容。
Autoencoder和Adversarial Autoencoder都是无监督学习,因为在训练过程中我们并没有世人任何label信息,但是如果利用图片的label信息则会帮助AAE去提取style信息而不受图片content的影响,这样我们的AAE就变成了一个监督模型。
模型
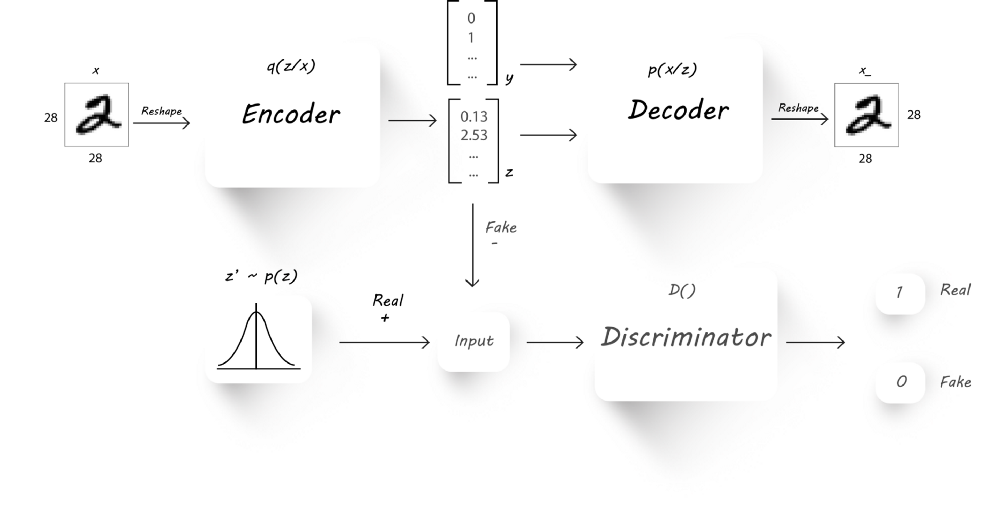
除了利用latent code作为decoder的输入,我们同时把标签y信息作为另一个输入,decoder利用这两个输入来生成图片。encoder学习图片的style,decoder利用该学习到的style和额外的内容信息y来重构输入图片
相比较于无监督AAE,唯一的区别就是decoder的输入:
- 来自encoder的latent code
- 图像标签的独热表示
训练
重构阶段
我们将输入图像送入encoder得到输出latent codez,然后将z和图像标签y串接起来成为一个更大的输入送入decoder。我们训练AE使最小化图片重构损失
正则化阶段
与无监督 AAE一样。
Python实现
Decoder
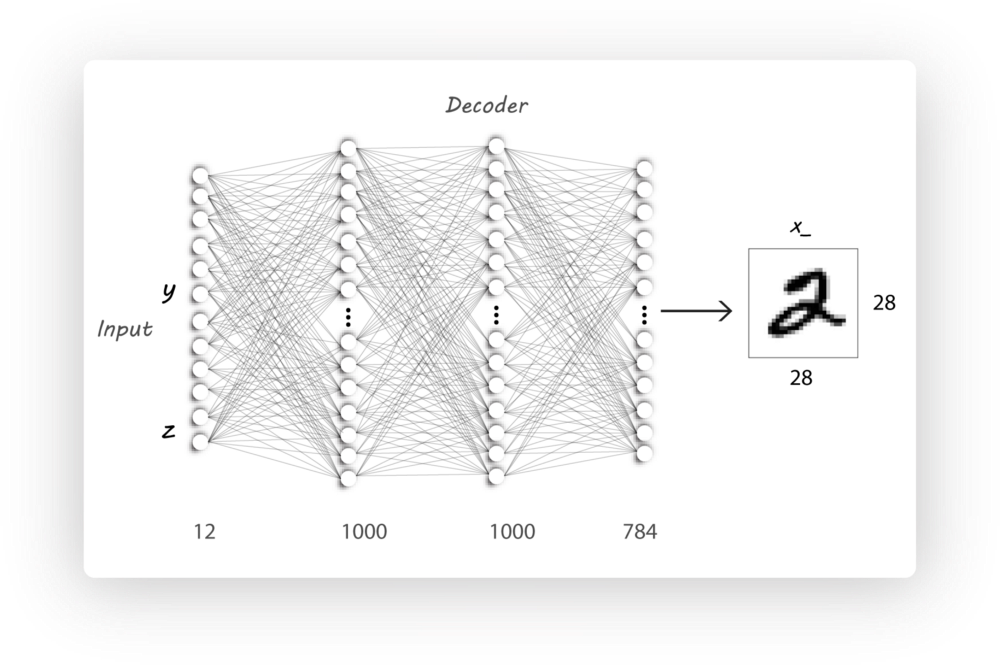
MNIST的图像总共有10类,则y的独热向量长度就是10,laten code的长度是2,则decoder的输入长度是(10+2)
|
|
GAN分类器
本节我们将介绍如何利用encoder对MNIST手写体进行分类,并与传统的神经网络分类器(NN)比较,为保证实验公平性,encoder和NN使用相同的结构。
我们首先介绍传统的NN分类器,如下图所示,
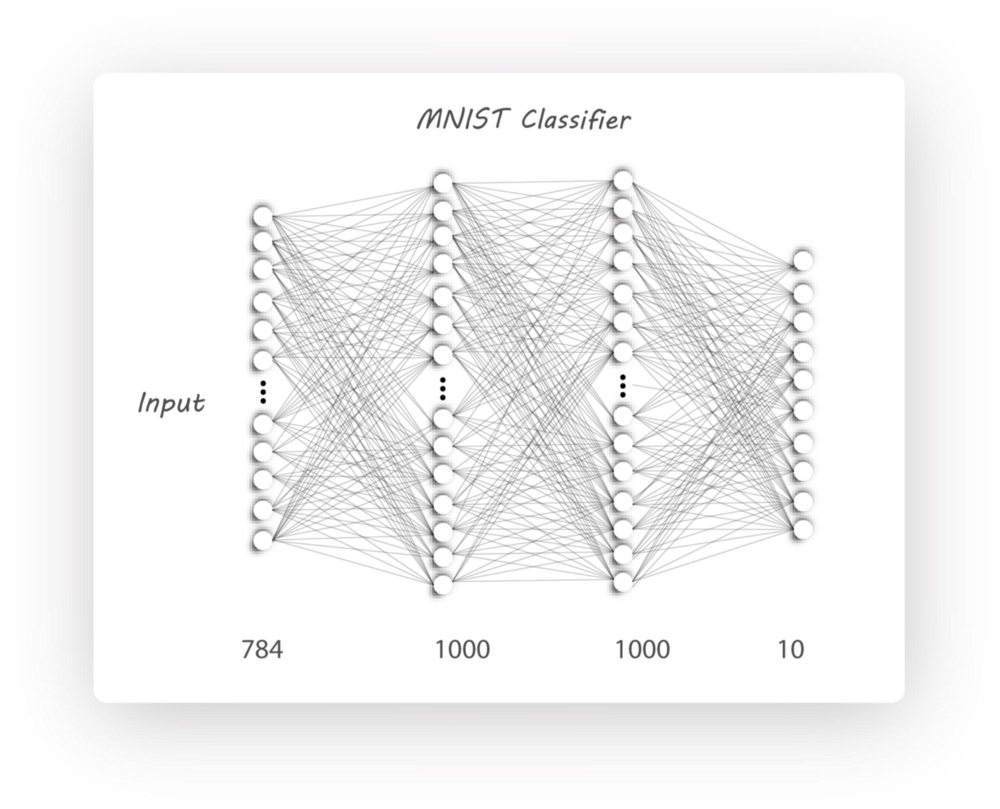
那么我们如何将encoder改造成为一个分类器呢?实际上,encoder分类器不仅能够提升分类准确率,还可以减少数据维度,从图片中分离内容和风格,我们的模型如下:
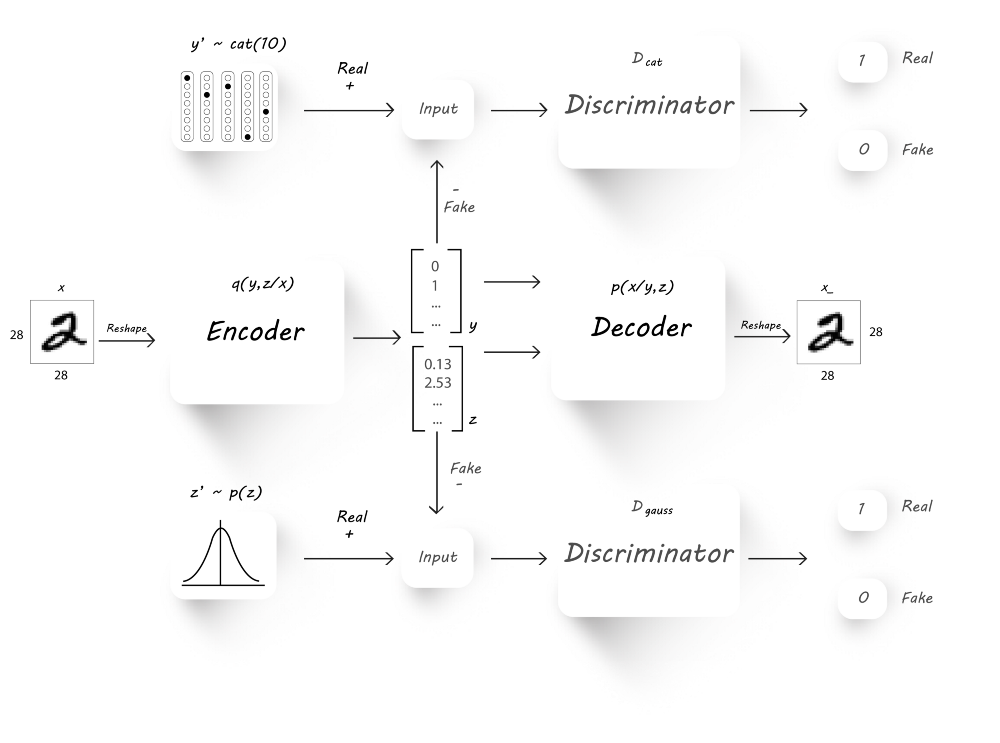
可以看到,我们增加了额外的discriminator($D_{cat}$),该分类器以对抗的方式与encoder一起训练,从而迫使encoder产生10维的独热分类向量
在AAE的基础上对encoder作了修改,此时encoder有两个输出:latent code(z)和classification(y),由于有10个类,则y为10维向量,而z的维度由用户决定。
图片重构阶段
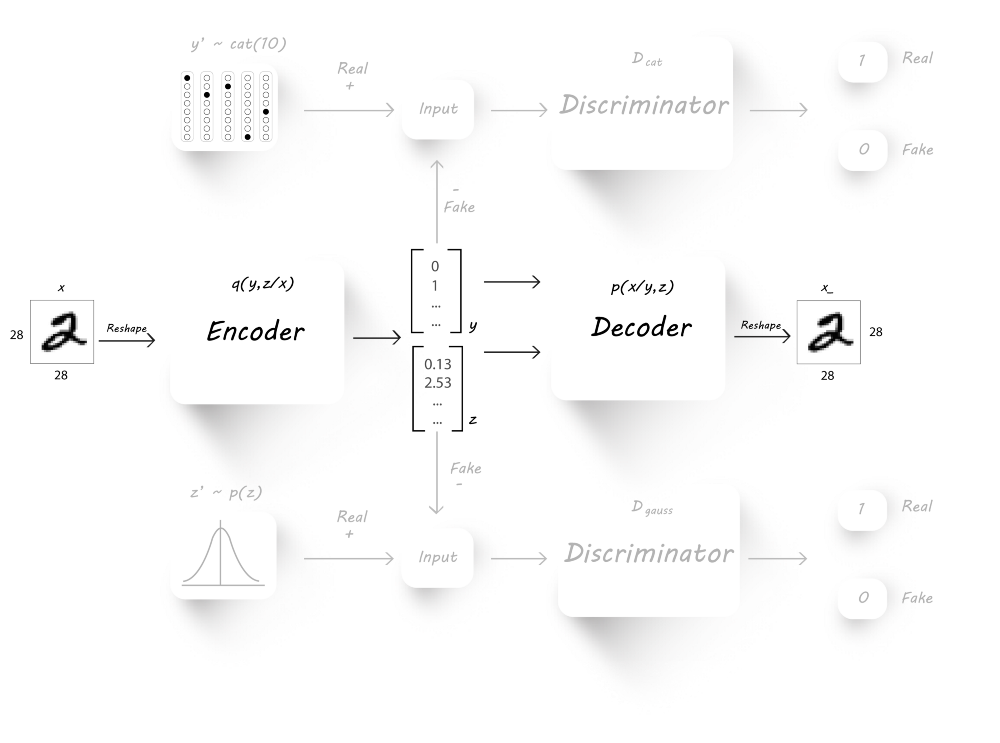
该阶段我们欲使生成的图片逼近我们的真实图片,所以我们使用MSE(mean squared error)来衡量输入图片与输出图片间的差异。
正则化阶段
该阶段由两个部分组成:$D_{cat}$和$D_{gauss}$的训练
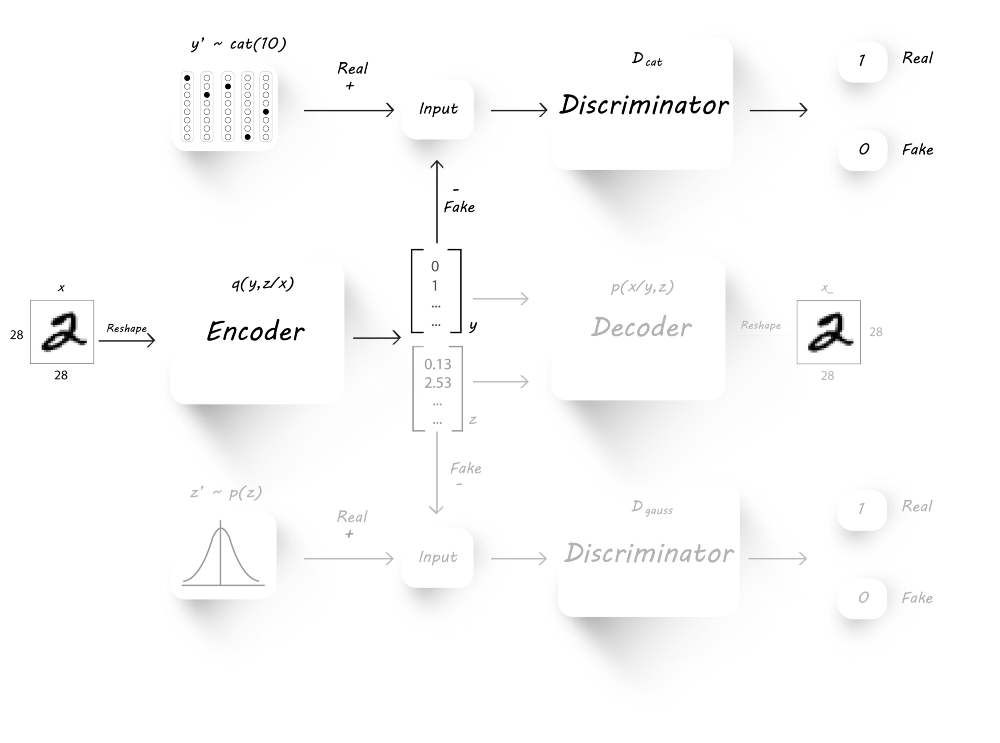
我们首先训练discriminator D_cat来辨别真实的分类标签$y^{‘}$和encoder生成的分类标签$y$。为此,我们将图片作为encoder的输入取产生$y$和$z$,然后将生成的$y$和真实的$y^{‘}$用于discriminator的训练。最后,我们固定分辨器的参数,并设置目标为1,训练encoder来欺骗分辨器。
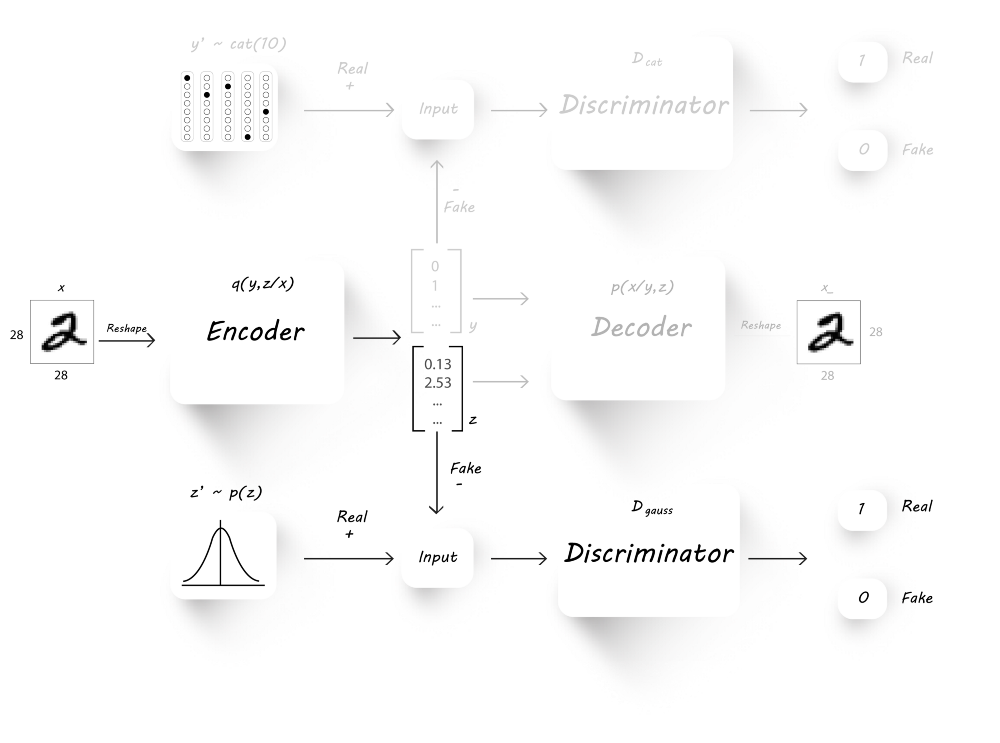
同样的,为了生成具有高斯分布的latent code(z),我们还需要训练分辨器$D_{gauss}$。
半监督分类器阶段
最终我们训练encoder来对手写体数字进行分类,目的是最小化生成的分类标签与真实的标签的交叉熵。
Python实现
Encoder
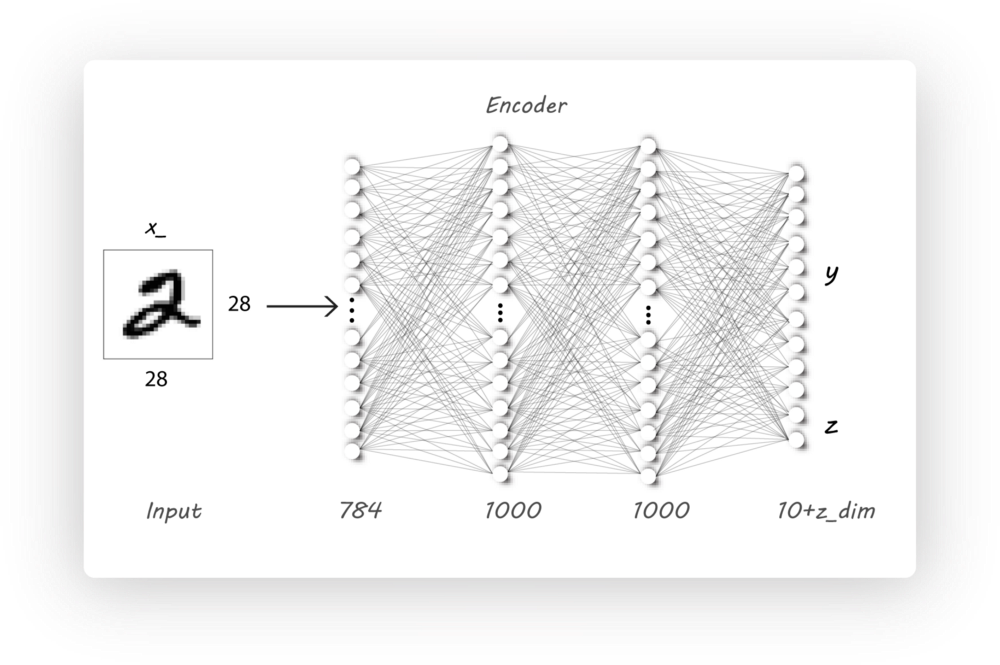
在原始encoder的基础上,只需要需改encoder的输出维度,增加对分类标签的输出
Decoder
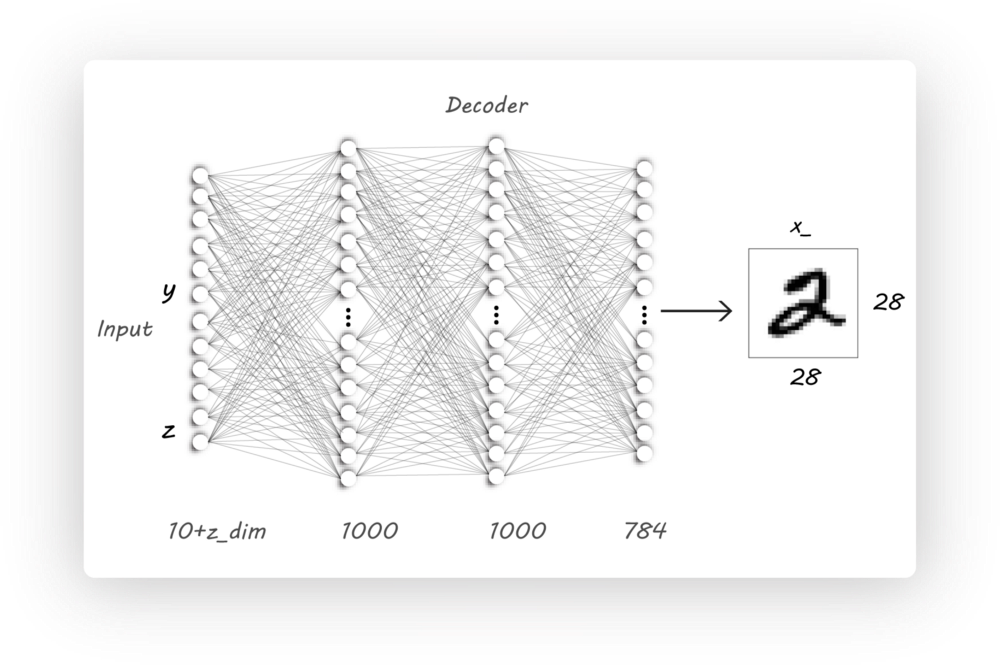
Discriminator
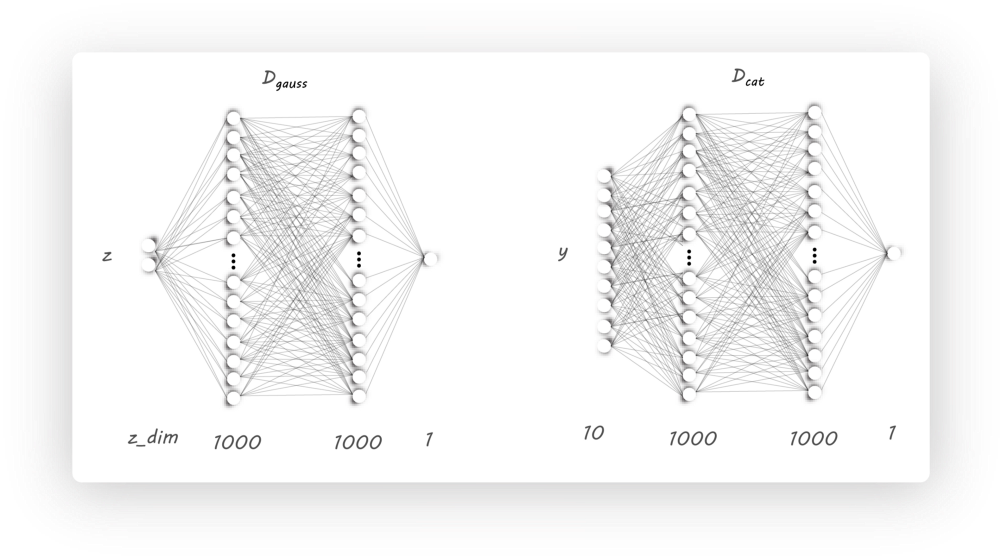
我们需要两个分辨器,它们除了输入维度不同,其他是一样的
CVAE-GAN
《 CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training》
Linear Regression
线性回归
模型
线性回归模型,顾名思义就是线性模型求解回归问题。
线性模型
【定义】给定具有$d$个属性的数据样本$x=\{x_1,x_2,…,x_d\}$,$x_i$是$x$在第$i$个属性上的取值,线性模型通过对属性的线性组合来进行预测的函数:
向量形式表示为:
其中$w=(w_1;w_2;…;w_d)$,只要确定了$w$和$b$,模型就得以确定。
向量都表示成竖直的一条直线。
回归问题
回归属于监督学习的范畴,用于预测输入变量与输出变量的关系。其本质就是数据拟合,选择一条函数曲线使其很好地拟合已知的数据,同时能够预测未知的数据。
按照输入变量的属性个数,分为一元回归和多元回归;按照输入变量和输出变量之间的映射关系,分为线性回归和非线性回归。
线性回归
线性模型描述的是属性间的组合关系,而回归问题求解的是输入与输出的关系。
即使用一个线性函数去建模输入变量属性间的线性关系,从而发现输入变量与输出变量的关系。给定数据集$D=\{(x_1,y_1),(x_2,y_2),…,(x_m,y_m)\}$,其中$x_i=(x_i1;x_i2;…;x_id)$。
问题描述:线性回归试图学习一个线性模型$f(x_i)=w^Tx_i+b$,使$f(x_i)\approx y_i$。
又称为多元线性回归,或者多变量线性回归。
算法求解
最小二乘法
只要确定了权重$w$和偏差$b$的值,那么我们就可以得到模型了,而我们想让预测值$f(x_i)$无限接近真实值$y_i$,所以使用均方误差作为性能度量,即我们试图让均方差最小:
均方误差对应了常用的欧几里得距离,基于均方误差最小化进行模型求解的方法称为“最小二乘法”,实际上,最小二乘法就是试图找到一条直线,使样本到直线的欧氏距离之和最小。
参数估计
Loss函数求导取极值
我们可以对损失函数$Loss$求导,并令导数为零来求得最优参数:
公式推导
偏导
求解b,$\frac{\partial{}E}{\partial{b}}=0$
则$b=\frac{1}{n}\sum_{i=1}^{n}(y_i-wx_i)=\bar{y}-w\bar{x}$
求解w,$\frac{\partial{}E}{\partial{w}}=0$
则$w(\sum_{i=1}^{n}x_{i}^{2}-n\bar{x}^2)=\sum_{i=1}^{n}x_iy_i-n\bar{y}\bar{x}$,故
梯度下降法
损失函数是:
参数更新:
即:
此时,$b=w_0$,$x_0=1$。
正则化的损失函数
此时目标函数为:
$w_0$不需要正则化
此时梯度下降法为:
Data Preprocessing
Feature Scaling
It involves dividing the input values by the range (i.e. the maximum value minus the minimum value) of the input variable, resulting in a new range of just 1.
Mean normalization
This involves subtracting the average value for an input variable from the values for that input variable resulting in a new average value for the input variable of just zero.
By combining the two techniques and adjust the input values as shown in the following formula:
where $\mu_i$ is the average of all the values for feature $(i)$ and $s_i$ is the range of values (max - min), or $s_i$ is the standard deviation.
Convergence Figure
In order to make sure that our algorithm runs correctly, we need to debug gradient descent. Make a plot with number of iterations on the x-axis. Now plot the cost function, $J(\theta)$ over the number of iterations of gradient descent. If $J(\theta)$ ever increases, then you probably need to decrease learning rate $\alpha$.
Summary
If $\alpha$ is too small, it could result in slow convergence.
If $\alpha$ is too large, it may not decrease on every iteration and thus may not converge, like the following pic:
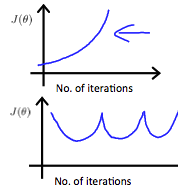
Example
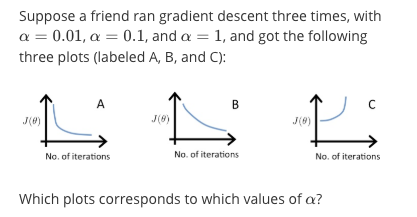
A is $\alpha=0.1$, B is $\alpha=0.01$, A is $\alpha=1$.
In graph C, the cost function is increasing, so the learning rate is set too high. Both graphs A and B converge to an optimum of the cost function, but graph B does so very slowly, so its learning rate is set too low. Graph A lies between the two.
Polynomial Regression
Our hypothesis function need not be linear (a straight line) if that does not fit the data well.
We can change the behavior or curve of our hypothesis function by making it a quadratic, cubic or square root function (or any other form).

例子
线性回归预测一维数据
来自Andrew Ng第二周的课程练习,给出城市人口及该市的商店利润,预测如何进行店铺扩展,即选择哪座城市开分店?给定的数据只有一个人口特征及利润目标值。
第一步就是进行数据的可视化。
|
|
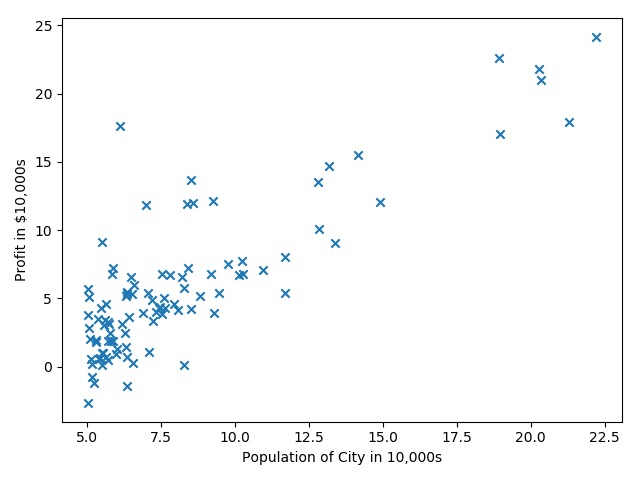
第二步:数据处理及参数初始化
我们为数据增加一列全一
|
|
第三步:损失函数
我们使用公式
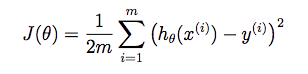
初次调用,返回值是32.07。
|
|
第四步:梯度下降法
检查梯度下降法是否正确的一个手段:查看损失函数是否在逐步减小。我们使用梯度更新公式:
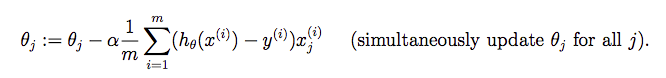
|
|
需要注意的一个点是:loss = ( y_pred - y )。反过来的话,会出现loss趋于无穷大。这个是对loss函数求导得到的,无论$(h_\theta(x)-y )^2$还是$(y-h_\theta(x) )^2$,都是一样的。
第五步:可视化拟合曲线
|
|
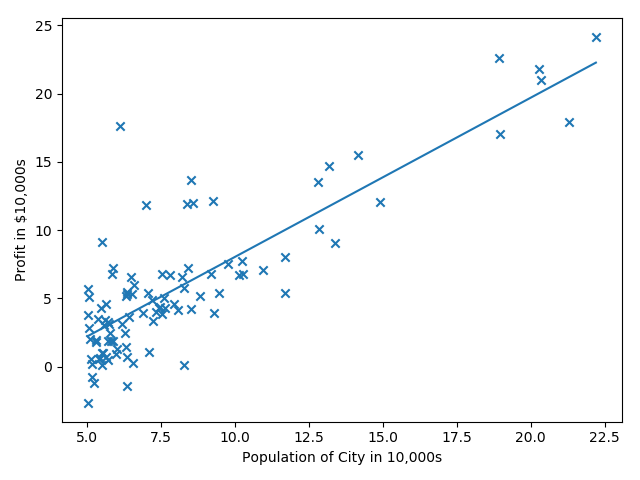
线性回归预测多特征数据
我们使用线性回归预测房价,数据集有两个特征:第一列是房屋面积(单位:$feet^2$),第二列是房间数,最后一列是房价。
特征正则化
发现两个特征数据范围相差特别大,所以需要对数据进行正则化,这样可以加快梯度下降法的收敛。
- 减去均值
- 除以标准差
正则化之后,别忘记加一个全一列。
注意:记得存储mean和std的值,这样我们在预测位置数据的时候,第一步就是使用mean和std对未知数据做同样的处理。
|
|
梯度下降法
先实现损失函数
|
|
再实现梯度下降法,损失函数都是10次方。
|
|
Linux命令
文件
退出保存
|
|
利用scp远程上传下载文件/文件夹ref1
统计文件个数
|
|
|
|
设置屏幕分辨率
|
|
删除
删除目录下所有文件
用通配符*英文星号可以表示“所有文件”这个概念,所以删除文件夹下所有文件的方法就是,先用cd命令切换到这个文件夹下,然后执行rm ./*命令表示删除当前目录下所有的文件,但是注意,如果文件夹下有子目录,这条命令就无法生效了,因为它无法删除子目录(删除子目录要加上-r选项)。
Keras
Keras使用技巧。
TODO
- [ ] LSTM
- [ ] CONV1D
- [ ] TIMEDISTRIBUTED-VIDEOS
- [ ] FIT_GENERATOR
- [ ] STATEFUL_RNN
AutoEncoder
AutoEncoder通过设计encode和decode过程使输入和输出越来越接近,是一种自监督学习过程,输入图片通过encode进行处理,得到code,再经过decode处理得到输出,我们可以控制encode的输出维数,就相当于强迫encode过程以低维参数学习高维特征。
Generative Adversarial Networks
Richard Feynman说“如果要真正理解一个东西,我们必须要能够把它创造出来。”
GAN 启发自博弈论中的二人零和博弈(two-player game),GAN 模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型 G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越像真实样本越好;判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率。
Variational AutoEncoder
AutoEncoder(自编码器)本质上是数据特定的数据压缩。虽然自编码器中的重构损失函数确保了编码过程原始数据不会丢失过多,但是没有对约束特征$z$做出约束。
作为一种无监督的学习方法,VAE(Variational Auto-Encoder,变分自编码器)是一个产生式模型,其在ae的基础上约束潜变量$z$服从于某个已知的先验分布$p(z|x)$,比如希望$z$的每个特征相互独立并且符合高斯分布等。